⭐ Отчёт о VB-Trend 2021 и изменения в Smart Monitor
Двенадцатого ноября 2021 года в Москве на площадке Crowne Plaza Moscow – World Trade Centre состоялась восьмая конференция VB-Trend 2021: Knowledge Center, посвященная вопросам комплексного мониторинга и информационной безопасности.
Ниже мы делимся ключевыми результатами VB-Trend. Со всеми докладами и видео-материалами можно ознакомиться на официальном сайте мероприятия.
Вам стоит прочитать этот обзор в следующих случаях:
Вы были на VB-Trend, но ничего не поняли 🙂
Вы были на VB-Trend, но все забыли после дегустации виски!
Вы не были на VB-Trend, но интересуетесь Smart Monitor!
Содержание
Новая версия Smart Monitor
Максим Кириенко | VolgaBlob
В первой части доклада, посвященной функциональной доработки платформы Smart Monitor, мы представили новый механизм background-запросов, который позволяет отправлять сложные и ресурсоёмкие запросы в фоновое исполнение и в момент их готовности моментально получать доступ к их результатам. Для исполнения этого механизма в Smart Monitor применяется свопирование результатов на диск (инструмент Smart Monitor Data Holder).
С прошлого релиза увеличилось и число аналитических команд поискового языка Smart Monitor Language.
Разработчикам теперь доступны следующие новые команды:
- inputlookup, позволяет выгрузить данные из справочника (lookup);
- outputlookup, с помощью которой возможна запись результатов запроса в справочник;
- iplocation, которая определяет IP адрес и добавляет в результаты дополнительные поля;
- rest, нужная штука для самодиагностики платформы мониторинга;
- rex, позволяющая во время поиска, «на лету» извлечь нужные значения с помощью регулярных выражений;
- makeresults, которая создает записи с временной меткой;
- addinfo, добавляет к каждой записи поля, которые содержат общую информацию о поиске;
- и еще мы сделали столь нужную для работы команду transaction для связывания событий в определенном промежутке времени.
Этот механизм позволяет контролировать размещенный в публичных хранилищах исходный код на предмет утечек конфиденциальных данных (пароли, ключи доступа и пр.), создавать и управлять инцидентами на основе найденных данных и объединять их с другой информации из вашего корпоративного хранилища.
Важные архитектурные изменения коснулись ядра платформы Smart Monitor, которое стало более открытым для сторонних разработчиков.
В 2021 году мы реализовали SDK, позволяющее создавать на платформе самостоятельные приложения с законченной прикладной логикой. С применением Development Kit стало возможным получить доступ к API Smart Monitor, что позволяет встроиться в контекст Smart Monitor, интегрироваться с навигационным меню, ролевой моделью, API выполнения запросов и т.д.
Аналогичную возможность с применением специализированного SDK можно применить для встраивания в Smart Monitor любой пользовательской визуализации.

В ресурсно-сервисной модели в версии 1.6 Smart Monitor мы прикрутили хронологию изменения метрик и индикаторов, которая доступна в виде timeline строки с историческими значениями за последние 30 дней или в виде детальной тепловой карты.
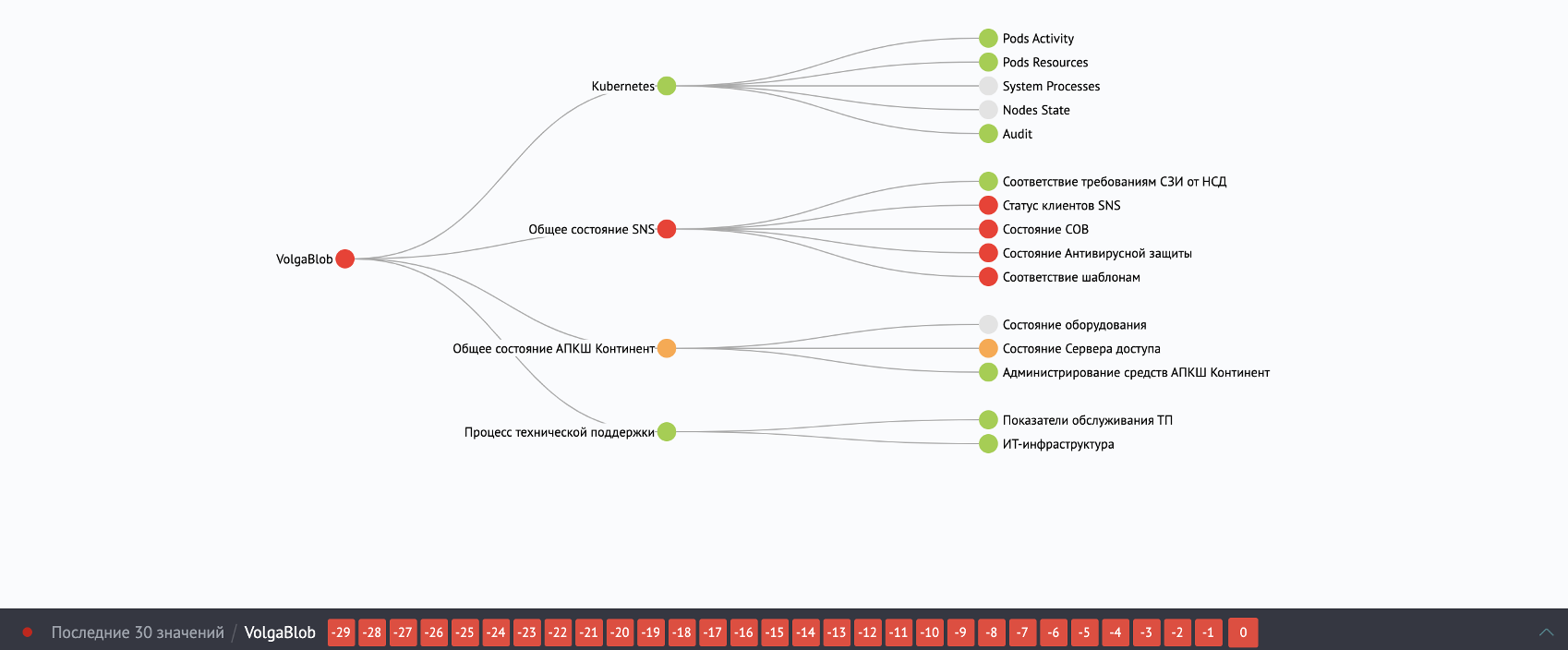
В интерфейс платформы интегрирована глобальная строка поиска (Spotlight), которая позволяет найти любой объект Smart Monitor (метрику, корреляционное правило, объект написанного на платформе внешнего приложения).
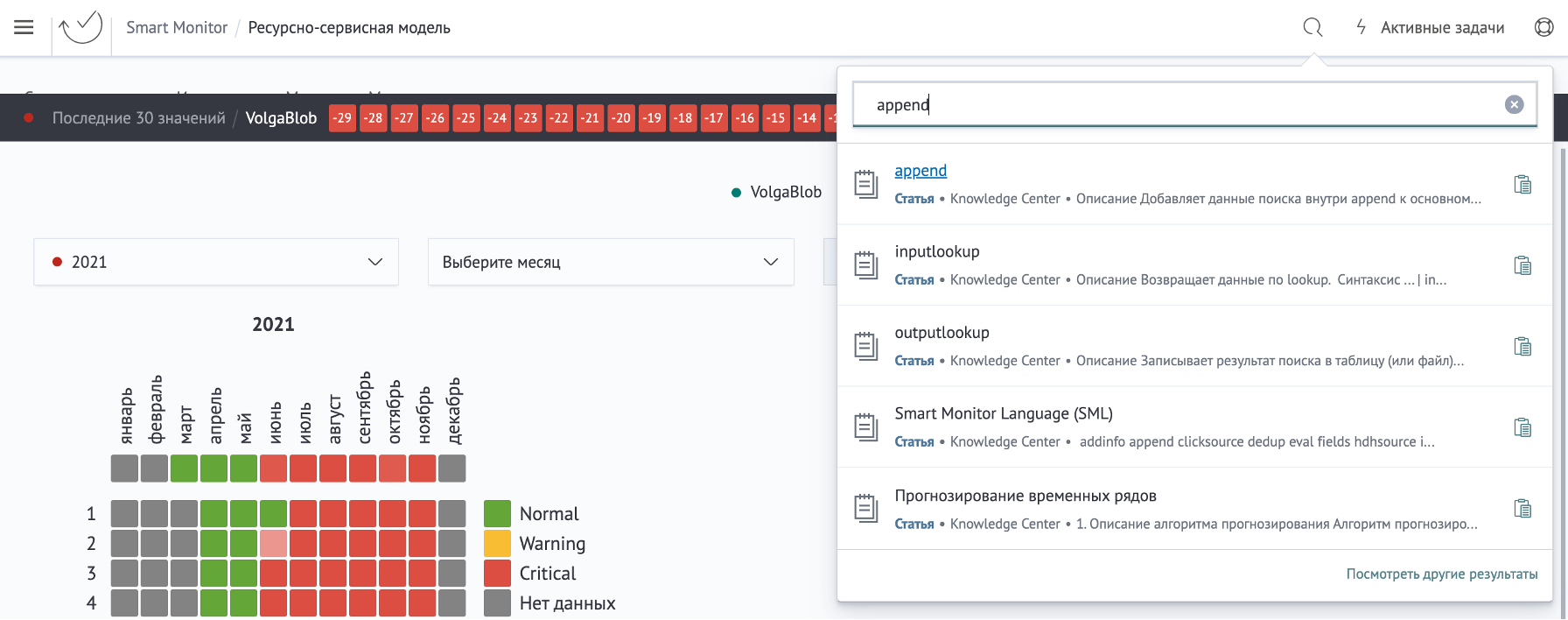
В разделе про планы развития мы представили наше видение того, куда может двигаться разработка в 2022 году.
Векторы развития Smart Monitor в 2022 году
Вот ключевые векторы развития, которые мы сгруппировали по сегментам целевой аудитории:
Разработчикам
Framework для пользовательских команд и реакций. Мы планируем добавить инструменты для создания и встраивания пользовательских команд в язык запросов. Т.е. если для решения кейса требуется алгоритмы, которые проблематично реализовать с помощью имеющегося в системе набора команд, пользователь имеет возможность оформить этот алгоритм, как собственную команду и встроить в Систему. Это касается Action-ов, действий, реакций при срабатывании запросов по расписанию. Мы планируем предоставить пользователям возможность, наряду с типовыми действиями, такими как заведение инцидента, отправка email, соощения в месенджер – создать произвольную логику реакции, встроить в систему и использовать.
Plugin Builder – инструмент для разработки собственных плагинов с применением Smart Monitor SDK. Plugin Builder представляет собой конструктор, в котором разработчик с помощью визуальных мастеров сможет создать элемент приложения Smart Monitor и сразу же зарегистрировать его в платформе.
Администраторам
Инструмент самодиагностики и мониторинга. Централизованные консоли для анализа и диагностики работы всех компонентов платформы.
Lookup Manager, JDBC Manager. Инструменты для удобной работы со справочниками и базами данных.
Компонент централизованного управления инсталляциями. Если у вас несколько инсталляций SM, например, использующихся разными департаментами или несколькими организациями в рамках Группы компаний, то с помощью данного компонента появится возможность централизованного мониторинга всех инсталляций, анализа подключенных источников, управления лицензиями, контроля доступов и ряд других функций.
Пользователям
Smart Monitor for MITRE ATT&CK. Модуль содержит инструменты для анализа применимости угроз/техник детектирования поведения злоумышленников, Risk-скоринга пользователей/хостов и анализа покрытия техник.
Функциональное развитие модулей . В следующем году мы сосредоточимся на функциональном наполнении следующих модулей: User Behavior Analytics (модуль предназначен для анализа действий пользователей и обнаружения случаев отклонений от типового поведения ), NetMap (автоматическое построение карты сети на основе получаемой с сетевого оборудования информации), Machine Learning Engine (применение алгоритмов машинного обучения при анализе данных внутри Smart Monitor).
Анализ файловых хранилищ. Мы думаем приступить к задаче анализа документов различных типов, располагаемых на файловых хранилищах. Хотим переводить их в текст и осуществлять по ним поиск со всей мощью поискового движка SM.
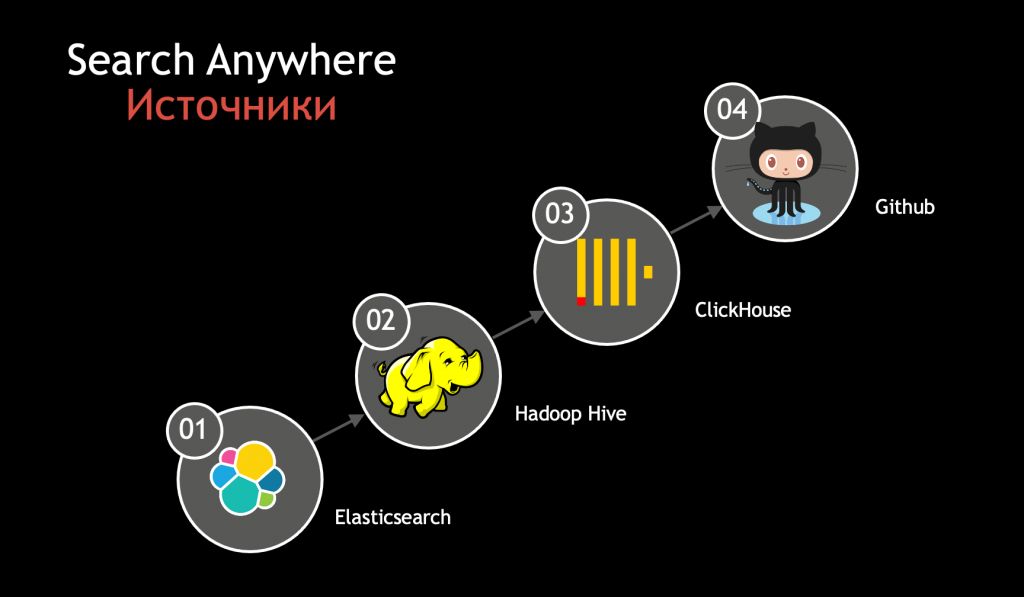
И, конечно, мы планируем развивать свою технологию Search Anywhere™.
Реализованная в платформе Smart Monitor концепция Search Anywhere™ позволяет осуществлять бесшовный поиск в различных хранилищах данных без необходимости их повторной индексации в единое облако данных. Это позволяет централизованно применять гибкость поисковых и аналитических инструментов Smart Monitor для связывания данных в гетерогенных средах хранения информации (DWH, Data Lake, СУБД).
В настоящий момент с помощью технологии Search Anywhere™ мы умеем анализировать данные в Elasticsearch, Hadoop, ClickHouse и Github.
Не время останавливаться!
Кто дочитал до этого места, тот явно неравнодушен, а значит в пару кликов может оставить своё мнение по поводу того, какое еще хранилище ему хотелось бы видеть подключенным в 2022 году.
Партнерам
Приложения. Мы открываем SDK и приглашаем к сотрудничеству технологических партнеров, чтобы вместе создавать на платформе Smart Monitor функционально законченные решения, выполняющие прикладные задачи клиентов. И зарабатывать на этом деньги, конечно. Уже в рамках VB-Trend мы согласовали участие в новой программе двух компаний, занимающихся разработкой. Для начала оформления технологического партнерства достаточно оформить запрос на нашем сайте.
Cloud. Мы решили дополнить On-Premise вариант установки облачным вариантом инсталляции Smart Monitor, и уже ведем переговоры с партнерами о размещении платформы в приватных и публичных облаках.
Обучение. В 2021 году мы формировали два обучающих трека – для разработчиков (Smart Monitor Developer) и для администраторов (Smart Monitor Admin), оба по два дня, с возможностью очного и дистанционного обучения. Почти доделали. До Нового года опубликуем программы, условия обучения и запустим первый набор. Само обучение начнется с 2022 года.
.pptx .pdf YouTubeОбзор изменений в модулях Smart Monitor
Александр Басов, Иван Силкин, Тимофей Мельников, Александр Скакунов | VolgaBlob
Incident Manager
Мы продолжаем развивать модуль Incident Manager, ключевой модуль управления инцидентами. В этом году к нему прикрутили механизм Workflow, позволяющий в зависимости от типа инцидента определять траекторию его расследования.
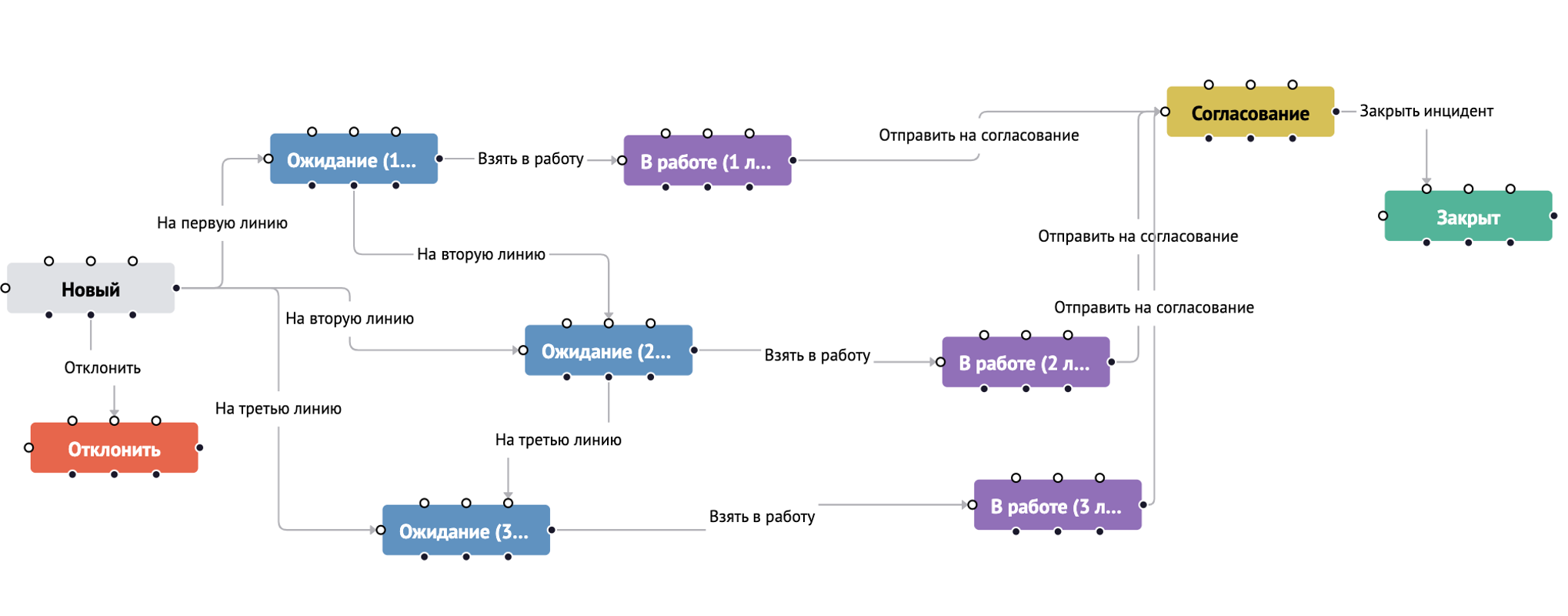
Механизм Workflow позволяет:
- формировать список статусов, которые может принимать инцидент;
- управлять логикой переходов между статусами;
- задавать ролевые ограничения для переходов между статусами;
- создавать неограниченное количество самих Workflow в системе;
- выбирать Workflow для правил, генерирующих инциденты;
- добавлять активные действия, выполняемые в процессе изменения статуса.
Inventory
Основное назначение модуля – формирование единой базы активов, а так же поддержание этой базы в актуальном состоянии в любой момент времени. Под активами здесь понимаются любые объекты инфраструктуры: серверы, рабочие станции, пользователи и так далее. Этот список расширяемый.
Мы научили модуль принимать информацию из различных источников, которые служат для обогащения единой базы активов.
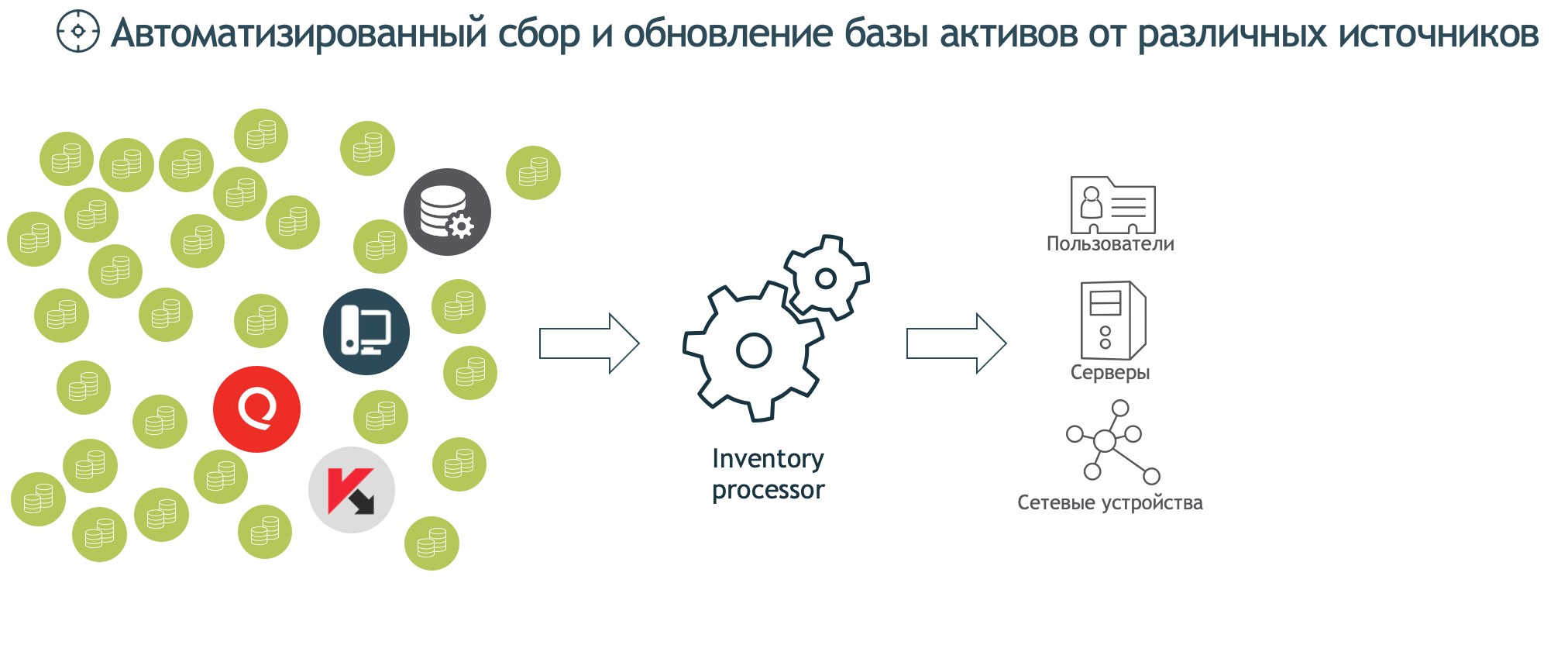
Данные инвентаризации мы также можем использовать в сочетании с событиями информационных систем при формировании правил выявления инцидентов безопасности.
Например: по данным инвентаризации сотрудник уволен, но в информационных системах продолжают регистрироваться события активности от его учетной записи. Мы можем создать инцидент по такому правилу.
Процесс формирования актива выглядит так:

Для верификации активов мы предусмотрели механизмы объединения и дедубликации активов на основе алгоритмов бинарного определения сходства с применением технологий цифровых отпечатков.
Это позволяет обогащать активы без риска захламления единой базы и автоматически отслеживать историю изменения активов.
.pptx .pdf YouTubeМониторинг выполнения требований Банка России
Илья Мельников | VolgaBlob

В этом докладе мы показали сценарий применения Smart Monitor для автоматизированной оценки соответствия ГОСТ Р 57580, который стал обязательным для финансовых кредитных организаций с 2021 года.
Процесс самооценки включает следующие шаги:
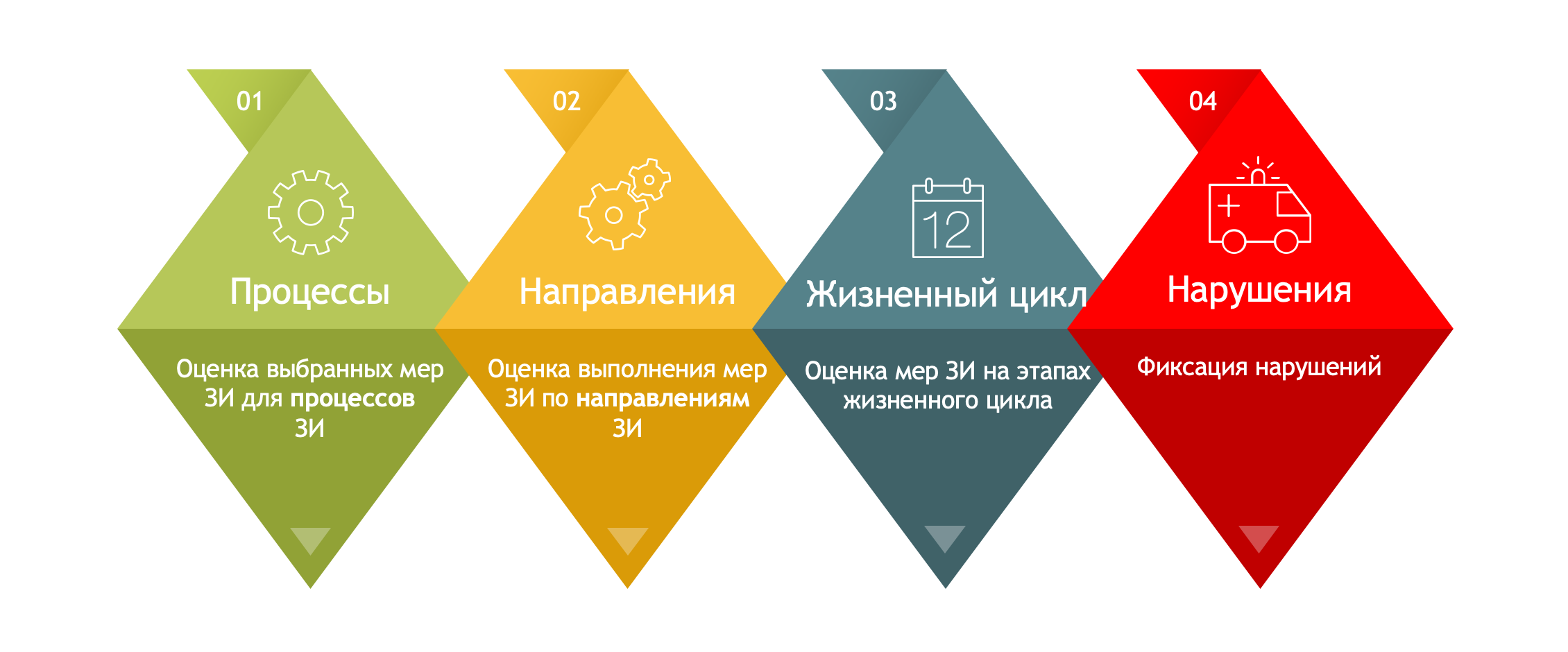
Актуальность автоматизации вызвана необходимостью контроля в рамках ГОСТ Р 57580 нескольких сотен технических и организационных параметров, что без прикладного инструментария представляет собой нетривиальную задачу.

Для отслеживания технических контролей стандарта ЦБ мы применяем алгоритмы автоматического вычисления сводного индекса соответствия по организации и инструмент ресурсно-сервисной модели.
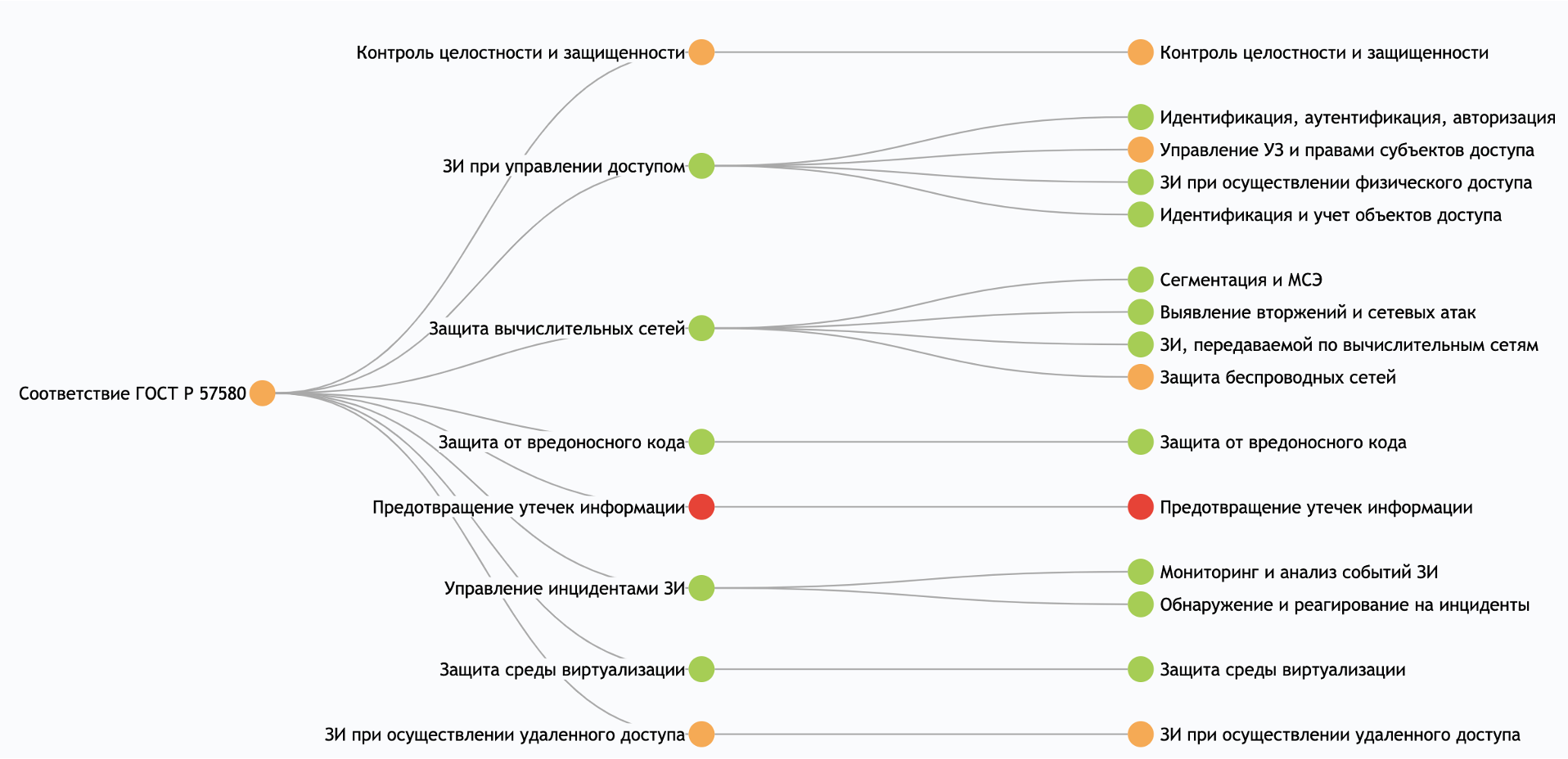
По результатам оценки соответствия формируется динамическая статья в модуле Knowledge Center, в которой автоматически вставляются диаграммы, показатели выполнений набора требований, комментарии, выдержки из стандарта и другая информация, которая обычно присутствует в отчёте о проведенном аудите.
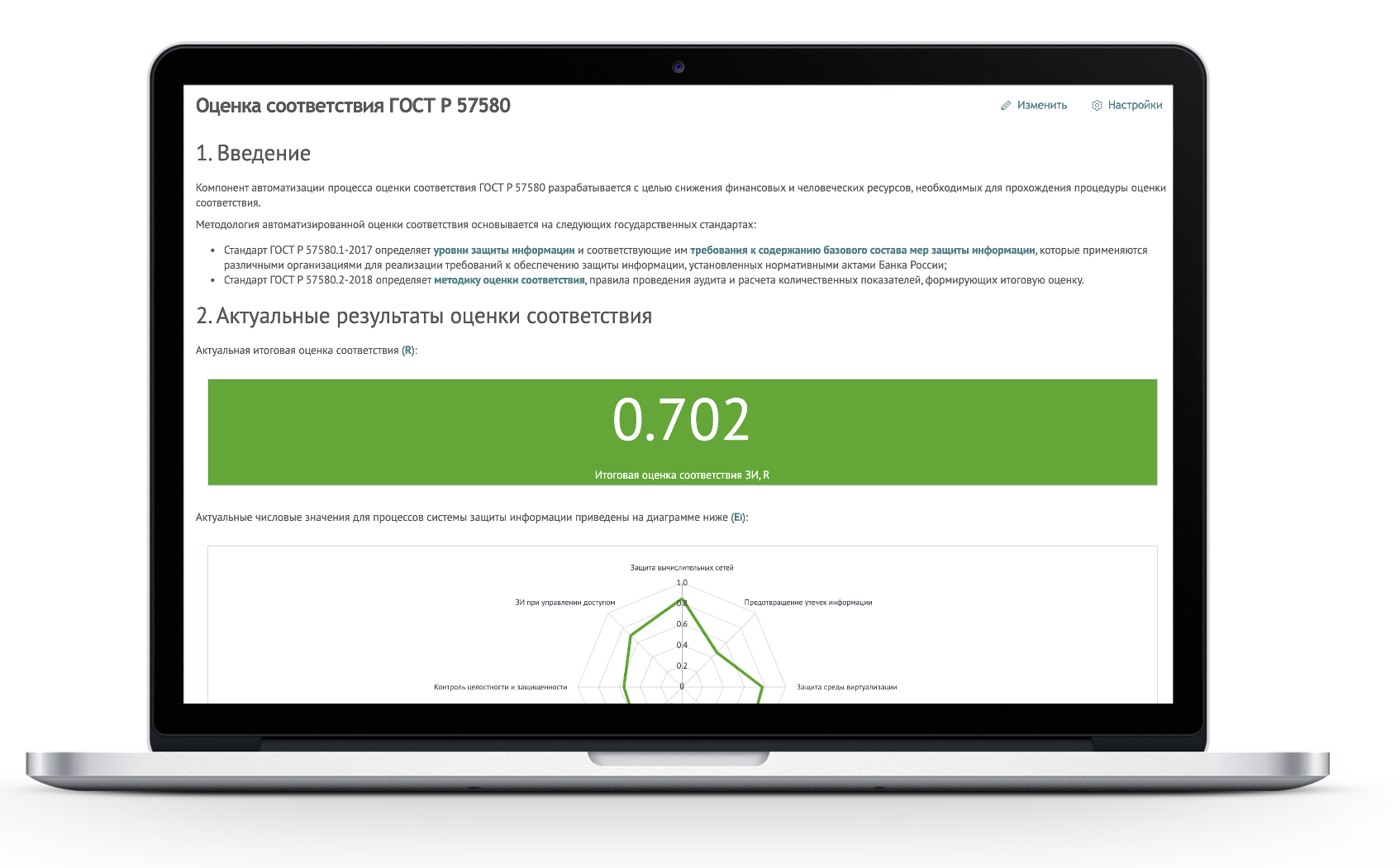
Благодаря применению Smart Monitor у вас есть возможность не просто получения статичного документа о текущем уровне соответствия ГОСТ Р 57580, который устаревает в момент создания, а интерактивного отчёта, актуального на любой момент времени!
Преимущества автоматизации оценки соответствия ГОСТ Р 57580 можно сформулировать так:
- Сокращение трудозатрат на процедуру оценки соответствия ГОСТ Р 57580.
- Работа со всеми этапами оценки соответствия в рамках SM.
- Возможность контроля оценки соответствия в реальном времени.
- Своевременное обнаружение нарушений.
- Возможность использования тех или иных результатов в виде динамических статей для конкретных должностных лиц.
Круглый стол “Возможен ли переход от Data-Driven к Knowledge-Driven концепции?”
Александр Скакунов | Директор VolgaBlob
Андрей Романчиков | Руководитель ЛокоТех-Сигнал
Евгений Пущенский | Руководитель Департамента ИБ АИМ Холдинг
Игорь Морозов | Ректор Академии АйТи
Михаил Сухов | Основатель и глава TechKarma Consulting
В рамках круглого стола организовали живую и откровенную дискуссию на тему формирования и использования корпоративных знаний. Вместо выводов приведем здесь несколько цитат из выступлений приглашенных экспертов. С полной видео-записью круглого стола можно ознакомиться по этой ссылке.


Если у нас получится найти людей, которые обладают природным любопытством и желанием добывать знания, то они эти знания добудут. Поиск таких людей должен вестись перманентно. Главный рецепт успешного использования ИТ-решений по управлению знаниями – это системность и регулярность их применения. Регулярность достигается правилом, что если ты не описал результат, то работу ты не сделал.
Андрей Романчиков | Руководитель ЛокоТех-Сигнал

Сотрудники должны чувствовать уверенность, что, передав свои интеллектуальные наработки, они не потеряют ценность для компании. Отсутствие такой уверенности превращает их из сторонников систем управления знаниями в “интеллектуальных шантажистов”. При этом в России слабая культура передачи знаний, и это вопрос не денег. Многие вещи делаются людьми бесплатно, пример та же Wikipedia. Нужно просто найти правильный подход к сотрудникам.
Евгений Пущенский | Руководитель Департамента ИБ АИМ Холдинг

На объемах сотрудников 1000+ методы неавтоматизированного наставничества не работают и потребность в ИТ-инструментах управления знаниями становится острой. В любой выборке людей найдутся энтузиасты, которые будут делиться знаниями. Вокруг них и надо организовывать процесс организации обмена знаниями. Чем больше коллектив, тем больше шансов выстроить работающую систему управления знаниями.
Игорь Морозов | Ректор Академии АйТи

Наиболее остро вопросы передачи знаний стоят в рамках процесса введения в курс дела нового сотрудника. Onboarding нового сотрудника однозначно предполагает наличие ИТ-систем, из которых можно черпать знания для оперативного погружения в работу. Ведение Wiki-инструментов не должно контролироваться, а должно строиться на самомотивации и самодисциплине. Проблема нулевого шага решается на уровне технологических лидеров (Knowledge Managers), которые смогут начать систематизировать свои знания. Дальше эта практика уходит в команды, где заполнение базы знаний становится правилом.
Михаил Сухов | Основатель и глава TechKarma Consulting

В качестве резюме сессии можно сказать, что несмотря на организационные и мотивационные сложности, ведение базы знаний в автоматизированном виде является целью организаций, которые хотят повысить эффективность своей операционной деятельности.
Как это предлагает делать наша компания, мы узнаем из следующего доклада про новое решение Knowledge Center.
Александр Скакунов | Директор VolgaBlob
YouTube
Новое решение по управлению знаниями – модуль Knowledge Center
Александр Скакунов, Максим Кириенко | VolgaBlob

В этом году мы пошли дальше, чем просто развитие платформы обработки машинных данных, и решили представить рынку наработку в области управления корпоративными знаниями.
В новом модуле Knowledge Center мы представили прикладное решение, которое позволяет писать статьи и добавлять на них дашборды. Т.е. совместили Big Data аналитику и человеческий опыт.
В качестве объектов знаний в Knowledge Center представлены все типы объектов, которые могут быть переиспользованы в Smart Monitor и представляют собой его контентное наполнение.
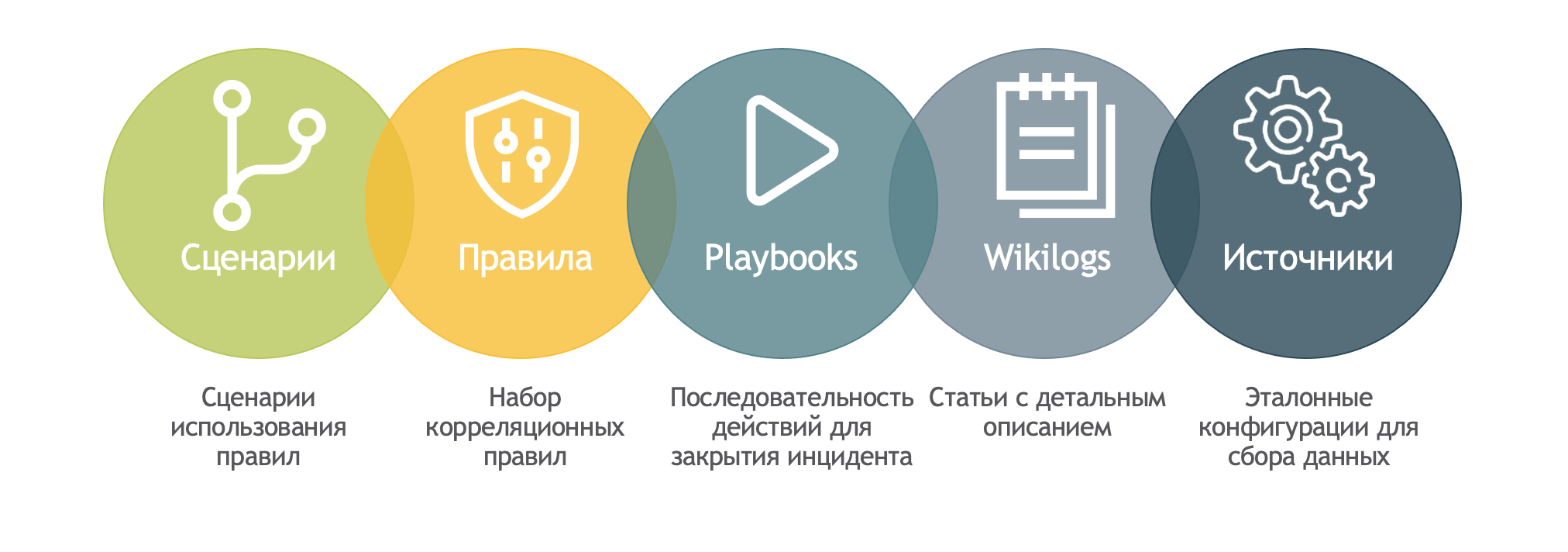
Разработчики и пользователи платформы с помощью Knowledge Center смогут делиться знаниями не только в визуальных витринах, но и с применением материала, созданного в полноценном текстовом редакторе.
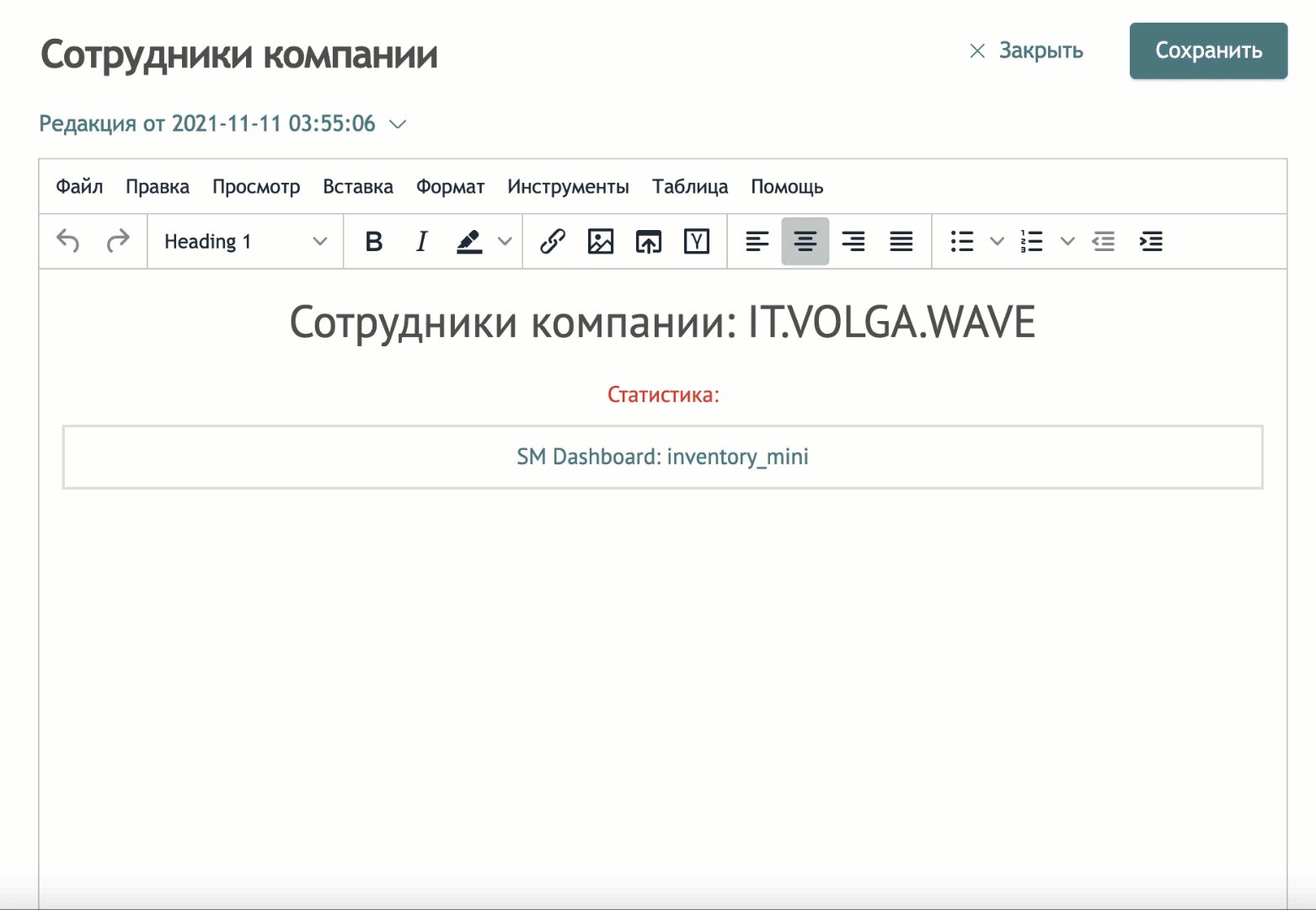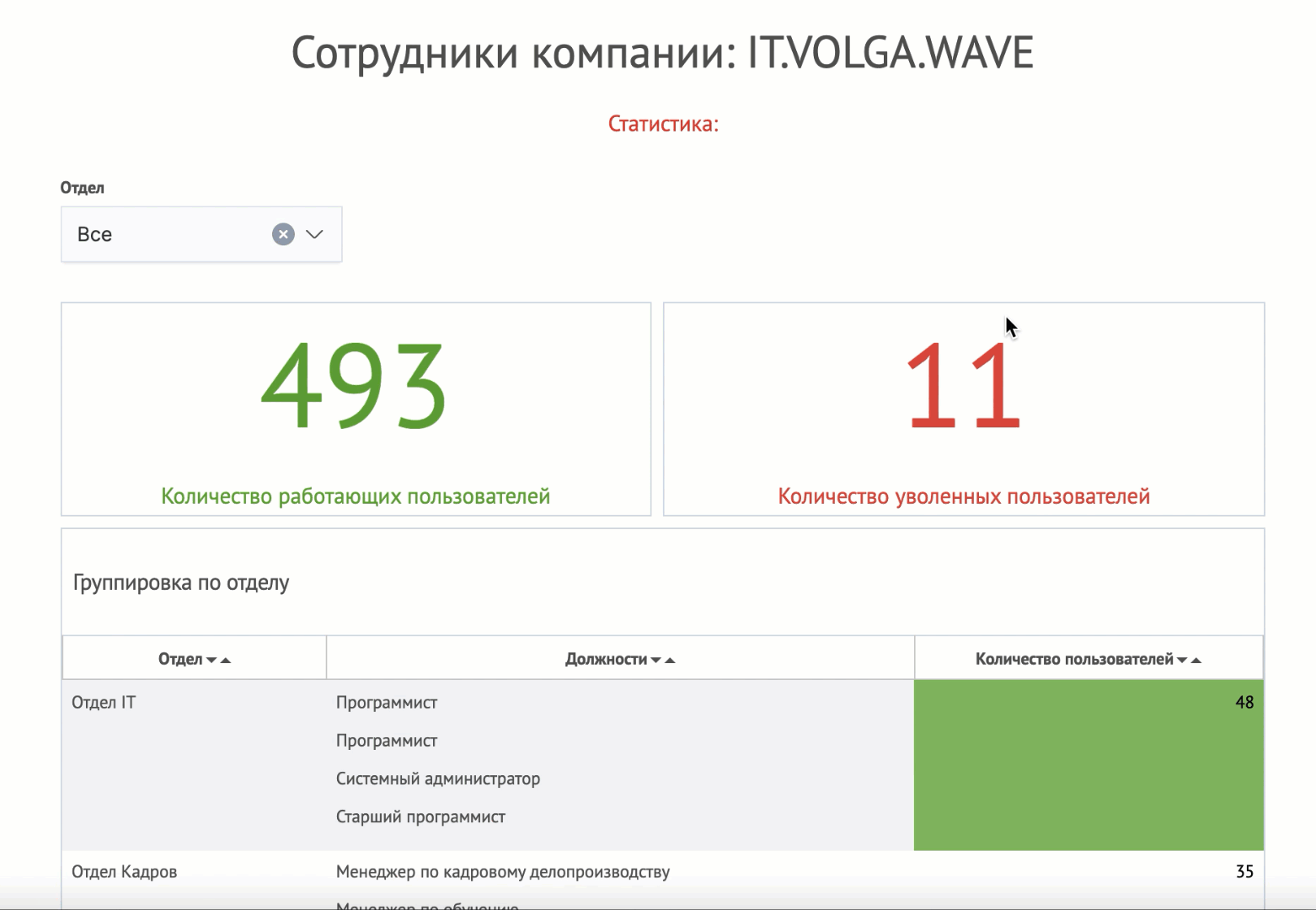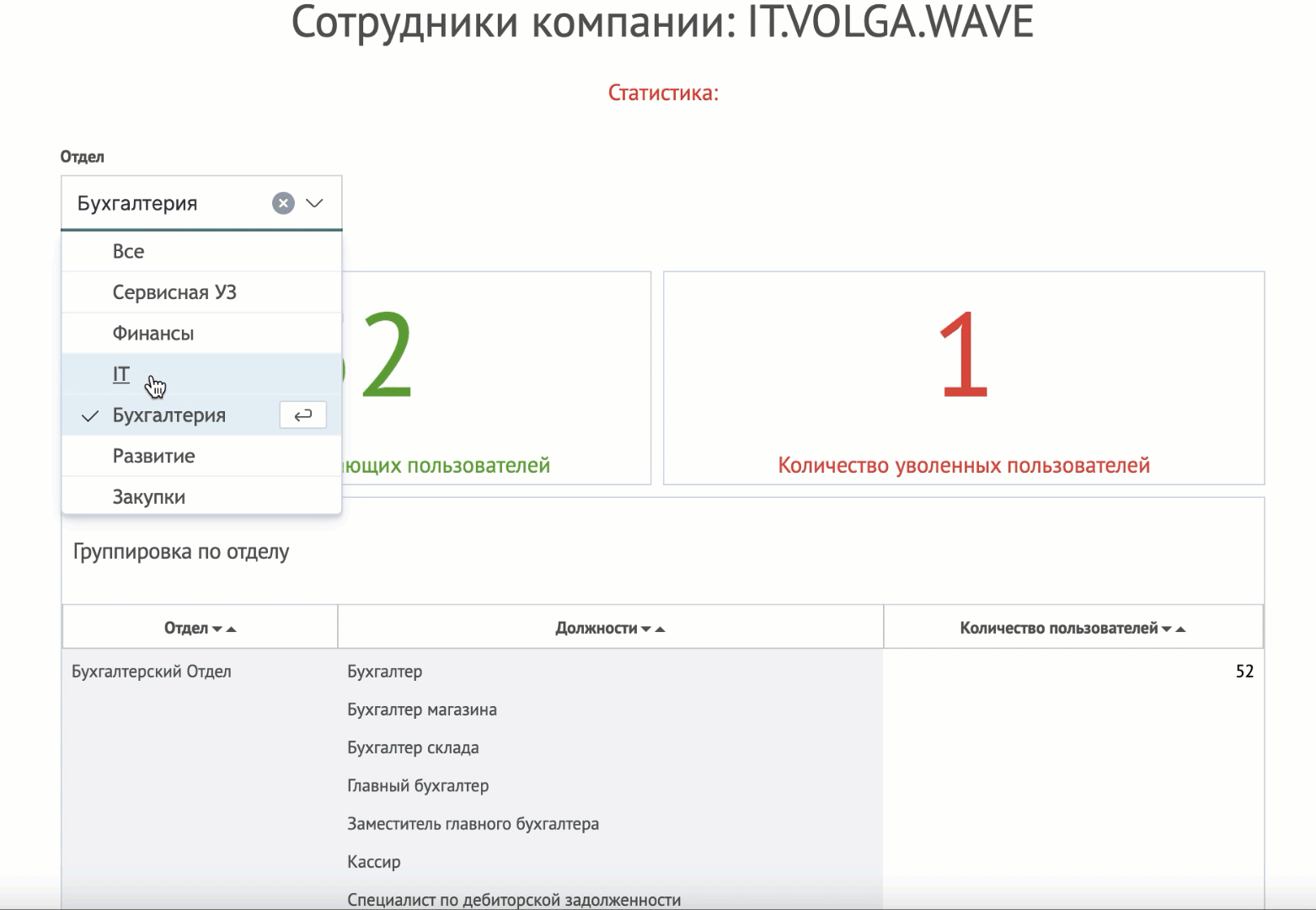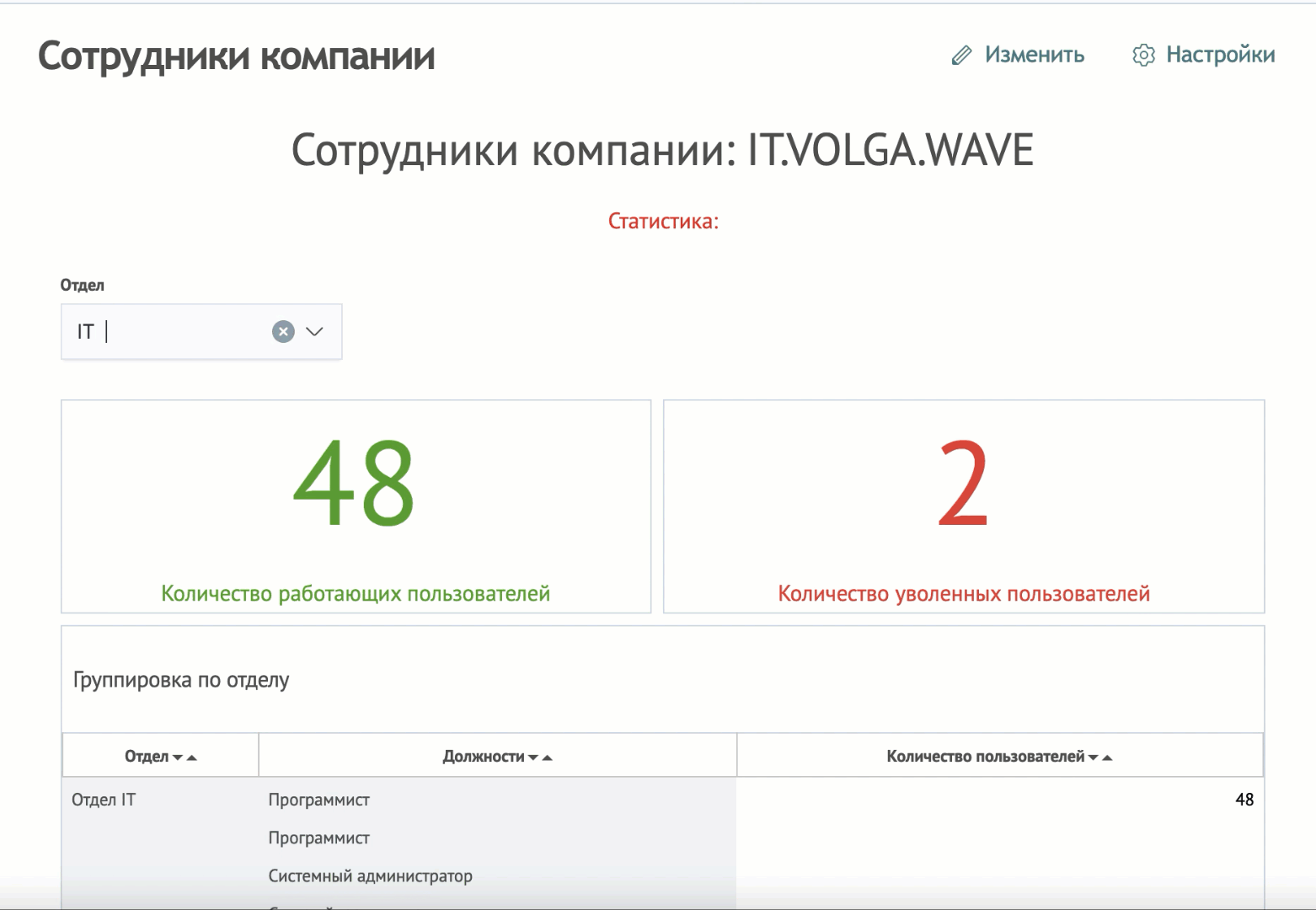
Модуль Knowledge Center интегрирован с инструментом создания диаграмм. Статьи, обогащенные диаграммами, могут содержать схемы сети, инфографику по бизнес-процессам и любую другую графическую информацию, которая сохраняется в векторном формате, централизованно редактируется и корректно отображается на всех типах устройств, включая мобильные.

Все модули Smart Monitor теперь обладают кросс-связями объектов (правил, сценариев, метрик и индикаторов и пр.), которые облегчают навигацию и поиск по элементам интерфейса.
Настроена возможность портирования объектов знаний в текущую инсталляцию. Для этого выбранный объект знаний (например, корреляционное правило) при портировании в инфраструктуру проходит визуальный процесс “привязки”, включающий выбор источников, подстановку специфичных для конкретной инфраструктуры параметров, и установку в нужный функциональный модуль платформы.
.pptx .pdf YouTubeТеперь обладатели контекстных подписок Smart Monitor могут быстро и с минимальными временными затратами внедрить настройки (правила, конфигурации, сценарии, метрики) в свою инфраструктуру без привлечения высококвалифицированных специалистов. А после этого дополнить Knowledge Center Wiki-статьями с корпоративными знаниями своих сотрудников.
Кластерные решения и нагрузочное тестирование Smart Monitor
Илья Шаманов | VolgaBlob
Темой этого доклада будет прошедшее недавно нагрузочное тестирование и полученные на нём результаты. Нас часто спрашивали, как Smart Monitor ведёт себя под высокими нагрузками, и теперь у нас наконец-то появилось достаточно данных для ответов на этот вопрос.
Цели тестирования
- Достижение работоспособности при потоке 10 ТБ/сутки
- Проверка работы кластера под высокой нагрузкой
- Проверка горизонтальной и вертикальной масштабируемости
- Формирование эталонных аппаратных конфигураций
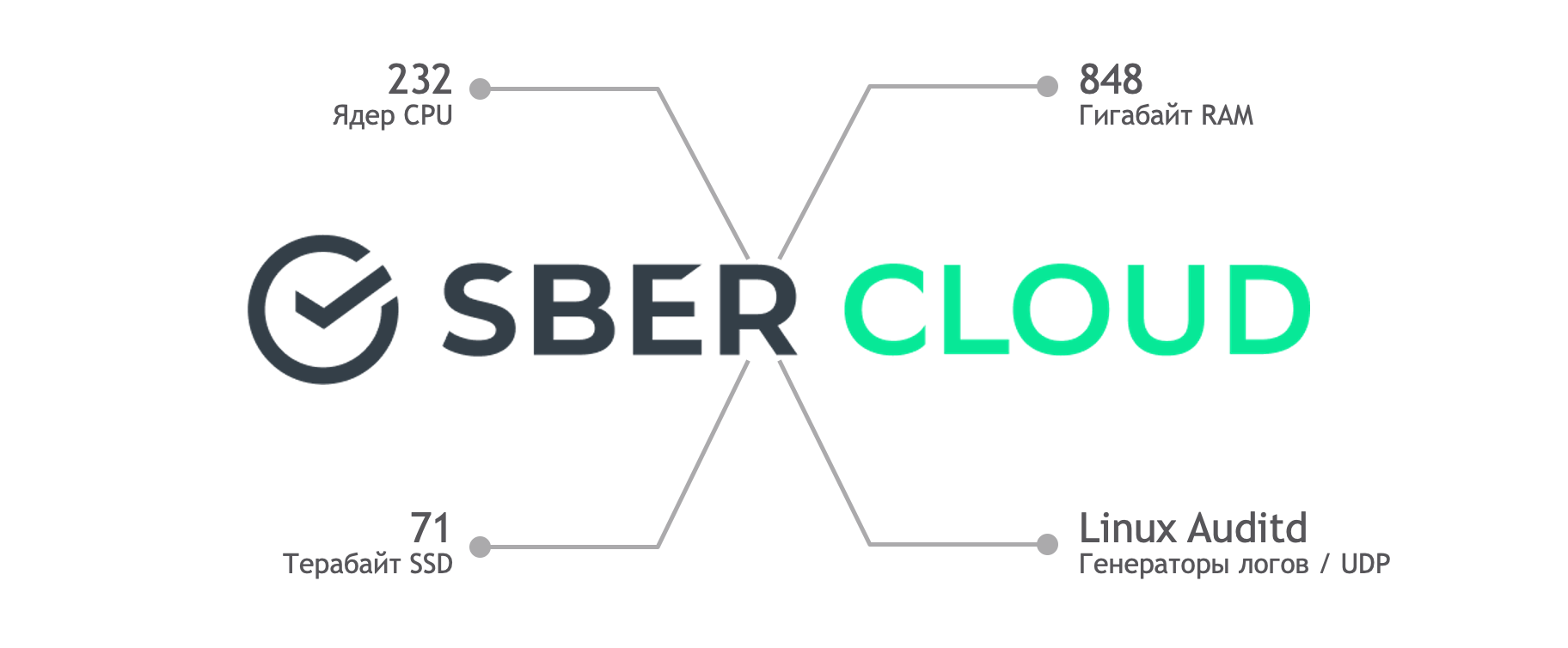
Сама идея этого тестирования реализовалась благодаря коллегам из SberCloud, которые предоставили нам достаточно серьёзный набор ресурсов для экспериментов. У нас было более 200 процессорных ядер, почти терабайт оперативной памяти и 71 терабайт хранилища. В качестве тестовых потоков данных использовались логи Auditd с различными настройками парсинга, для имитации данных различной сложности.
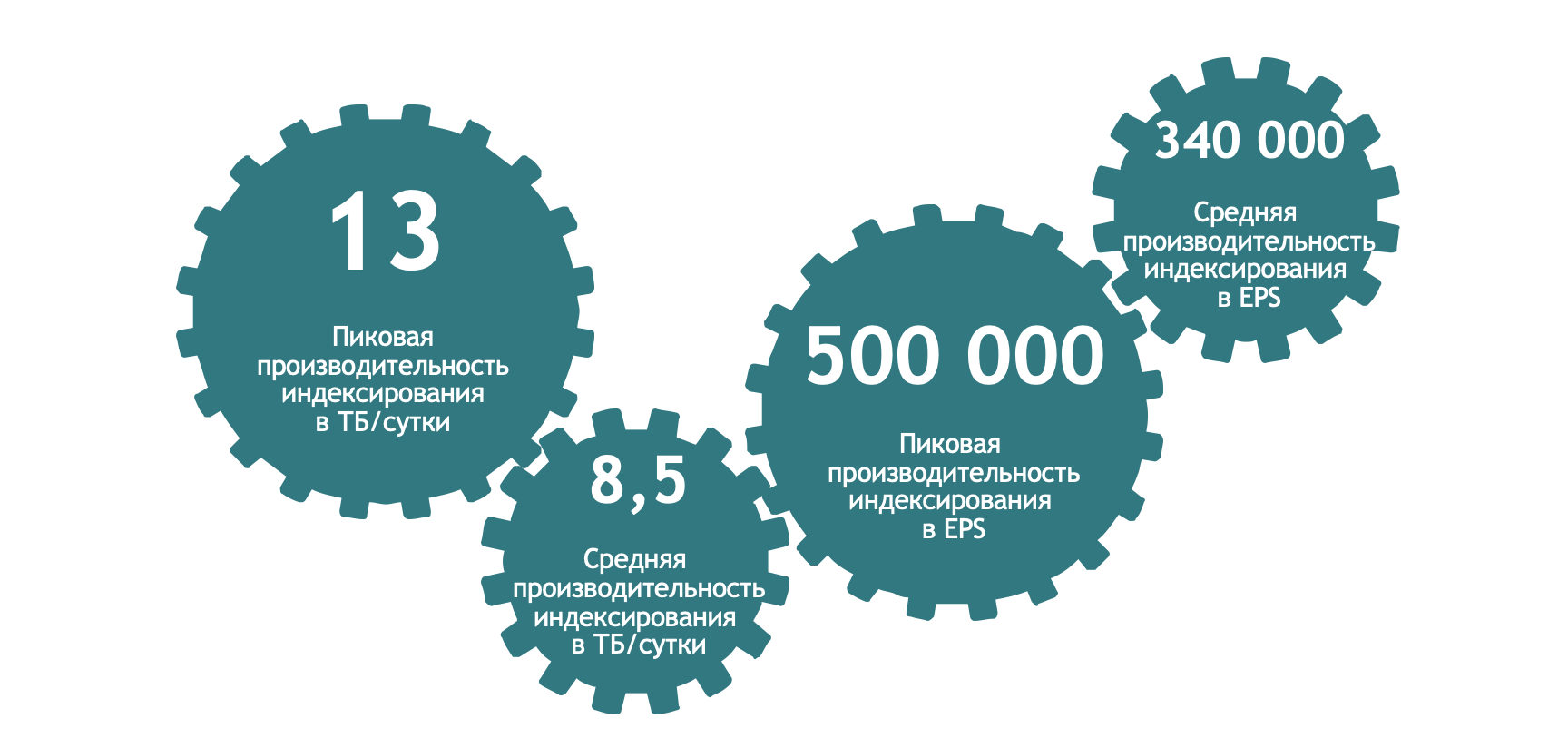
Мы провели работы со множеством различных конфигураций как отдельных серверов, так и кластеров. В итоге смогли получить достаточно впечатляющие показатели в виде среднесуточного объема 8,5 ТБ/сутки, а в пиковые моменты поток достигал 13 ТБ/сутки. Если смотреть на показатели событий в секунду, то это будет 340 тысяч в среднем и до 500 тысяч в пике. Таким образом, пусть и на небольшие периоды времени, тестовые инсталляции смогли преодолеть целевые 10 ТБ/сутки.
Интересным образом проявилась зависимость показателей от ресурсов отдельных серверов. Так, кластеры собранные из более маленьких серверов могли давать большую пиковую производительность, но при этом на длительных отрезках вели себя также или даже иногда отставали от кластеров с большими серверами.
Выбор типа масштабирования

Итог всех наших изысканий в части подходов к наращиванию инсталляций Smart Monitor мы свели в вот в такую таблицу. Как вы можете видеть горизонтальное масштабирование выигрывает в части удельной нагрузки на один сервер (она меньше), эффективности использования выделенных ресурсов и отказоустойчивости. Однако, у вертикального масштабирования есть свои плюсы за счет более простого управления инсталляцией – в ней банально меньше серверов, и простоты добавления ресурсов (хотя тут в основном речь идёт о виртуальных окружениях, где нарастить память или ядра не проблема). И отдельный плюс больших серверов – можно крутить очень ресурсоёмкие запросы, которые могут просто не поместиться, например, в память более маленьких машин.
А ещё в одной таблице мы собрали референсные конфигурации Smart Monitor для различных объемов данных.
Базовая инсталляция состоит из трёх серверов. По одному на каждую роль: веб-интерфейс, парсинг и фильтрация данных, роль индексирования и поиска. Такая инсталляция будет использовать некластерную лицензию SM Core и будет способна перерабатывать до 250 ГБ/сутки со сроком хранения данных до 20 дней.
Следующий тип инсталляции кластерный, и он уже потребует кластерной лицензии на SM Core, но и будет способен обрабатывать поток до 1 ТБ/сутки со сроком хранения проиндексированных данных до 14 дней. Здесь всё так же используется один сервер веб-интерфейса и один сервер парсинга, но на нём добавилось ресурсов. Помимо этого добавляется два сервера индексирования и поиска с теми же спецификациями.

И последний тип инсталляции, для больших потоков данных. Здесь вырастает как количество серверов, так и объём ресурсов на каждом из них, за исключением сервера веб-интерфейса, тот остался таким же, т.к. не выполняет какого-то значительного объема вычислений. Количество серверов парсинга выросло до 5 шт., и для сетевых источников данных может потребоваться дополнительный балансировщик, для распределения нагрузки между ними. Кластер серверов индексации вырос до 8 узлов, со значительно большими спецификациями. Такая инсталляция позволит обрабатывать поток до 10 ТБ/сутки со сроком хранения проиндексированных данных до 12 дней.
Это минимально необходимые ресурсы для работы с указанными потоками данных, и итоговый сайзинг под требования разных заказчиков на одном объеме может отличаться. Но, как минимум, эти данные можно использовать для понимания масштабов и первичной оценки.
.pptx .pdf YouTube