🇨🇳 Обзор платформы анализа данных Rizhiyi: китайский аналог Splunk
К нам пришёл запрос о сотрудничестве от китайской компании Beijing Yottabyte Information Technology Co., Ltd, которая занимается разработкой платформы Rizhiyi для анализа, обработки и мониторинга машинных данных. С 2014 года. Поисковый движок Beaver может рассматриваться как китайский аналог Splunk. Первый релиз был в 2018 году.
В логике наших китайских товарищей не упрекнёшь: VolgaBlob успешно развивал бизнес Splunk в России и продолжает поддерживать множество инсталляций Splunk. Так что тема с китайским аналогом должна была нас заинтересовать. Мы “клюнули”, изучили продукт, поработали на стенде, проанализировали кучу документации, провели общение с Rizhiyi и решили опубликовать результаты. 🧐
Кстати, мы честно в начале общения сказали, что тоже разрабатываем платформу по комплексному мониторингу, и её иногда называют “русский Splunk”. Товарищей это не смутило. Русская, американская или китайская платформа – не суть. Главное, что мы умеем из этого делать бизнес. Такая логика, наверно.
Название компании Rizhiyi можно перевести на английский как Easy Log. Дальше давайте вместе разберемся что это значит по мнению наших китайских коллег.
Содержание
Общее описание платформы
Платформа Rizhiyi позиционируется как интеллектуальный центр мониторинга. Он состоит из уровня приложений, реализующих бизнес-логику, уровня аналитической обработки и конфигурации и уровня сбора данных. Функциональную схему с этим трехслойным пирогом можно представить вот в такой картинке.
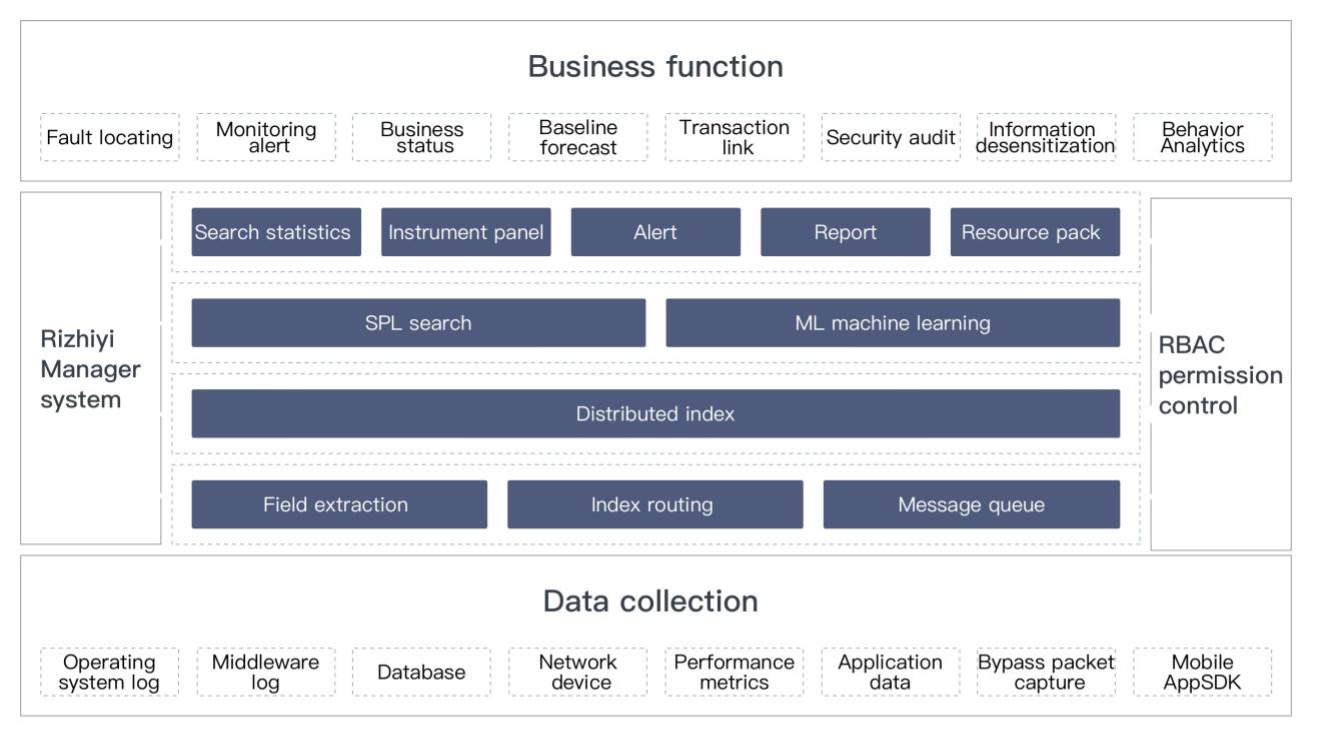
Заявленные сферы применения говорят об универсальности базовых механизмов работы с данными. Тут и бизнес-аналитика, включая поиск аномалий, и IT Operations и кибербез наш любимый дорогой (SIEM, UBA, SOAR, Compliance и вот это вот всё).
Весь функционал крутится вокруг поискового движка Beaver, который обеспечивает индексацию, анализ и жизненный цикл управления машинными данными. Это и есть “Китайский Splunk”. Его мы разбираем подробно тут.
Организация работы с источниками данных
Поддерживается безагентный сбор (syslog и пр.), для чего применяется слой rsyslog или syslog-ng серверов, а также сбор через два типа собственных агентов. Один легковесный полнофункциональный на Golang, другой на Java, с базовым функционалом, применяемый для UNIX-хостов. Есть еще проксирующий модуль, названный Agent-Proxy.
Очереди сообщений реализованы на Kafka, что призвано решать проблему бутылочного горлышка при индексировании данных. Это важно, ведь товарищи говорят, что система способна перемалывать сотни Тб в сутки 😵💫.
Для подключения источников созданы Wizard-диалоги, весьма удобные. По нашему мнению это одна из сильнейших сторон платформы.
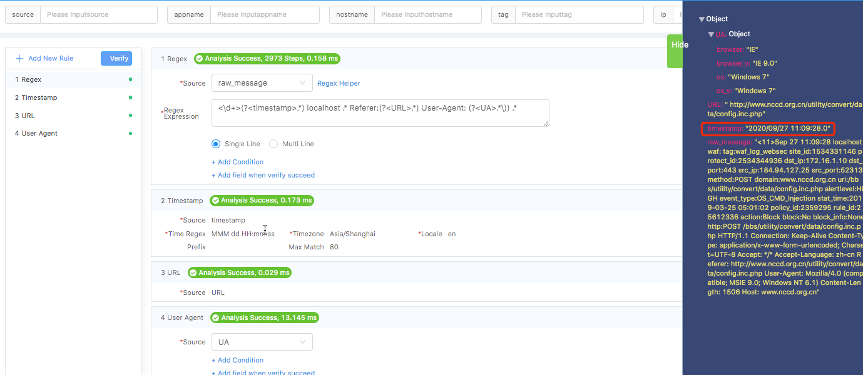
Механизм извлечения полей (Field Extraction) тоже очень удобный, в графическом виде пользователю дается возможность воспользоваться мастером извлечения и написать своё регулярное выражение.
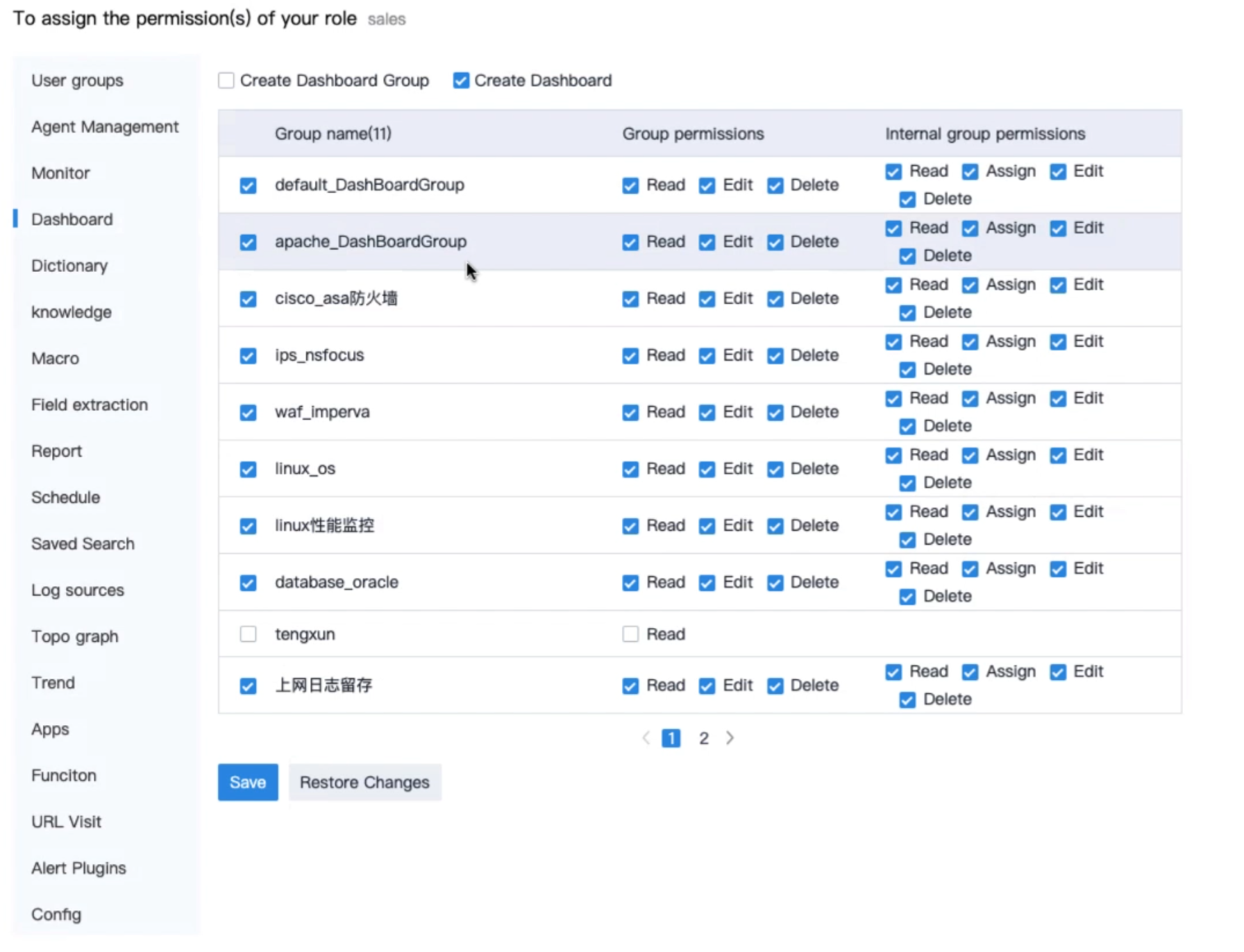
Ролевая модель предполагает интеграцию с AD, но не обладает возможностью гранулярного разграничения доступа на уровне данных. К сохраненному дашборду, впрочем, ограничить доступ получится.
Очищаются данные с применением компонента LogRiver. Дальше данные индексируются, и тут уже речь идет об аналитическом движке Beaver.
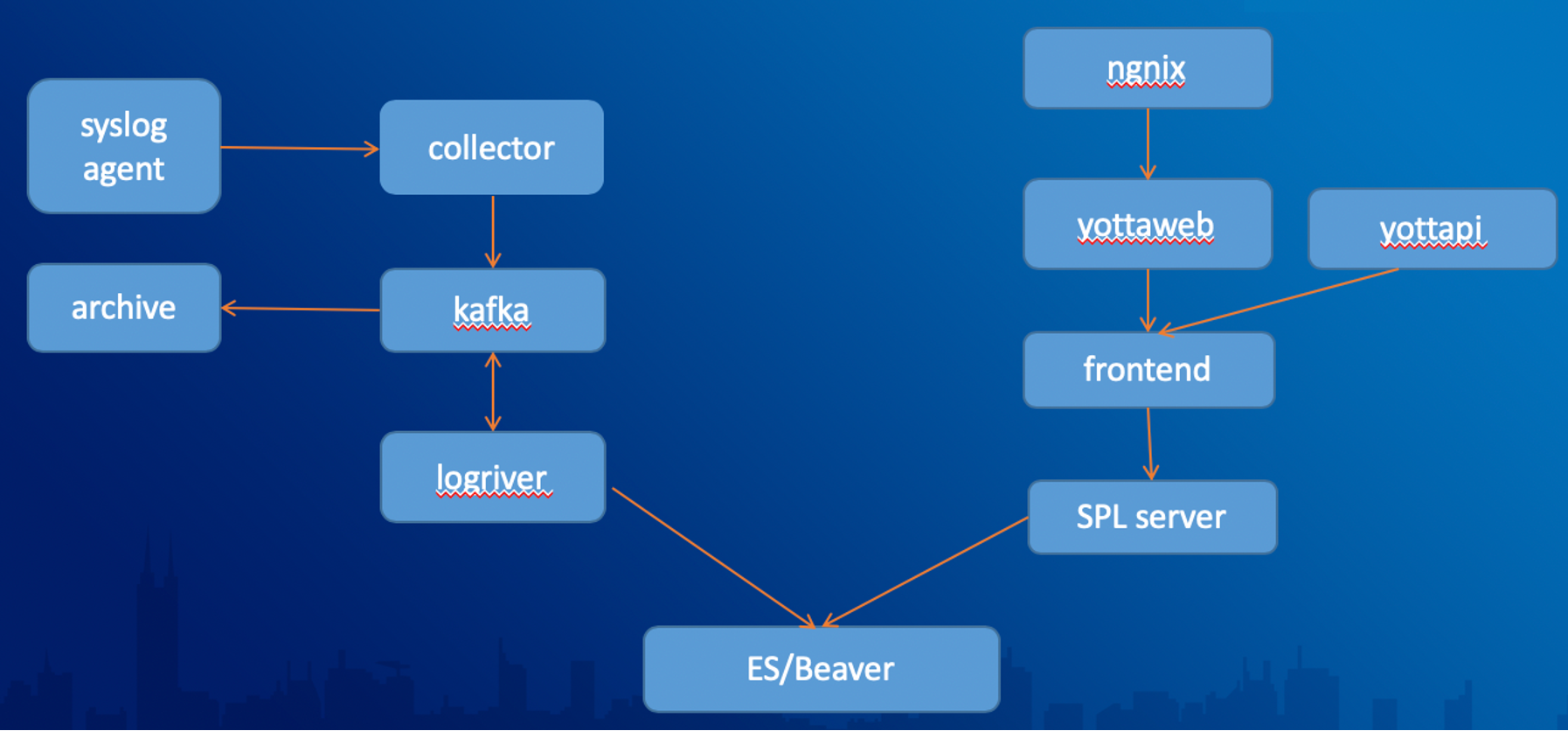
Система по анализу данных Beaver
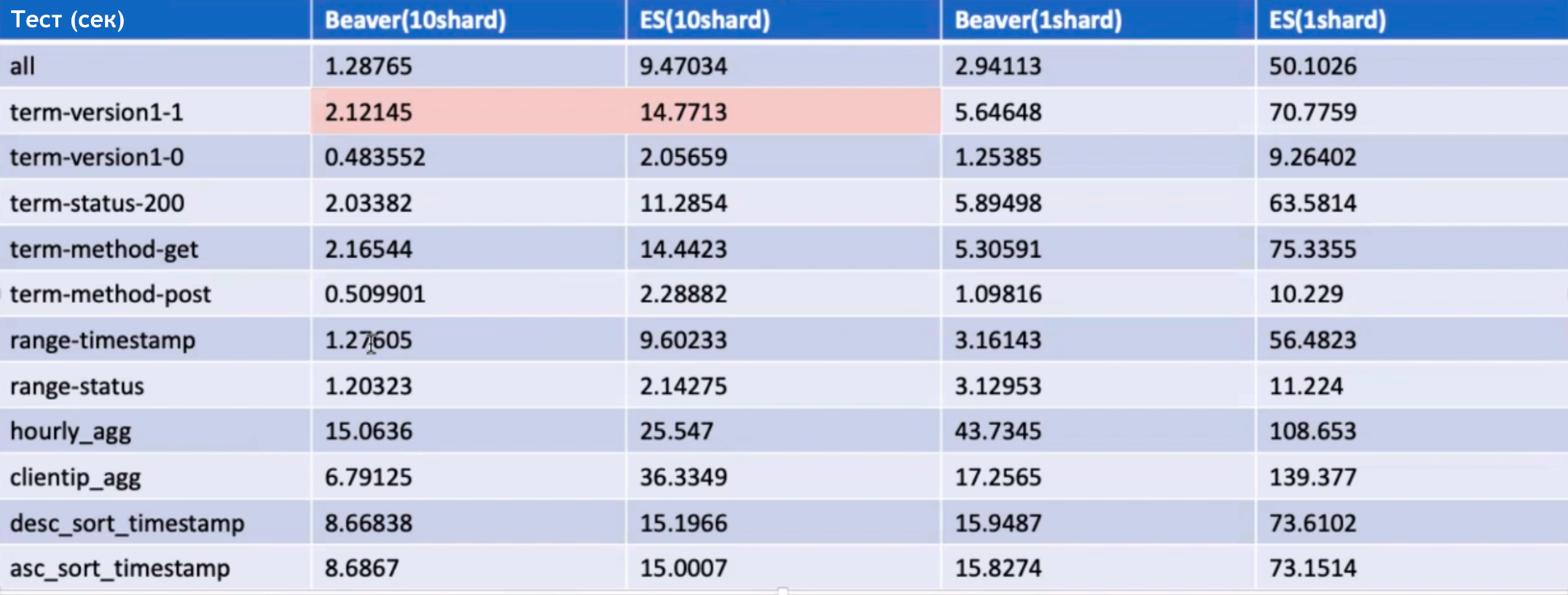
В основе Lucene (база ELK-стека), который производитель переизбрал в проприетарный модуль на C++ и использует в качестве индексатора. Эта сборка по заверению производителя позволила реализовать Real-time режим индексации данных, внутренние конкурентные потоки по записи данных и улучшило масштабируемость системы, а также автоматизировало перевод данных их горячих в теплые и затем в холодные индексы. Ок, не индексы, а шарды, коль скоро это Lucene.
Товарищи поделилились результатами тестирования, где они иногда в 7 раз обгоняют по скорости Elasticsearch. It’s not a magic, как говорится 😀
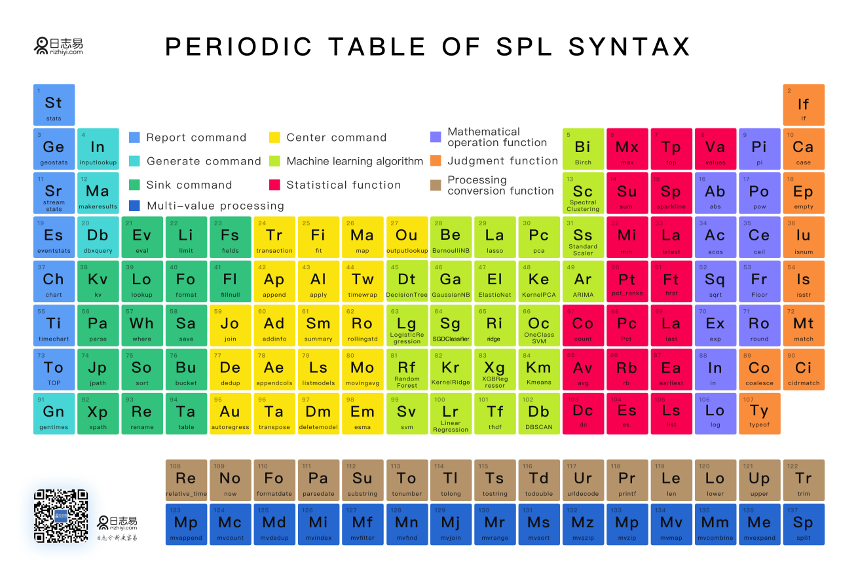
Search Processing Language
Внутри движка знакомый до боли SPL, без видимых невооруженным глазом синтаксических изменений. Товарищи запаковали анализатор в компоненту SPL Server, которая умеет работать с пайпами и воспринимает все ключевые Splunk-команды в режиме распределенного поиска. Вот вам “китайская таблица Менделеева” по поисковым возможностям Beaver.
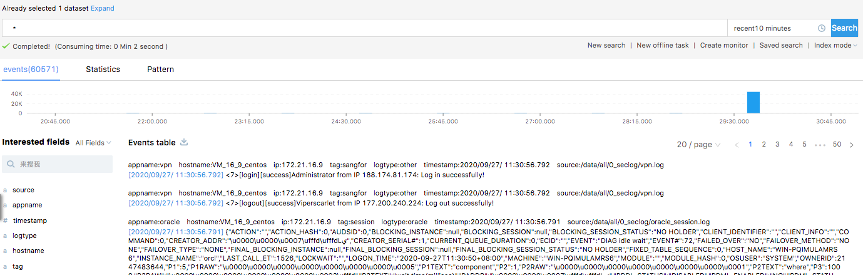
Для обработки ретроспективных запросов используется Spark, есть механизм фоновых запросов, чтобы не морозить пользовательский интерфейс сложными поисками.
Сам интерфейс поиска покажется пользователям Splunk и ELK очень знакомым.
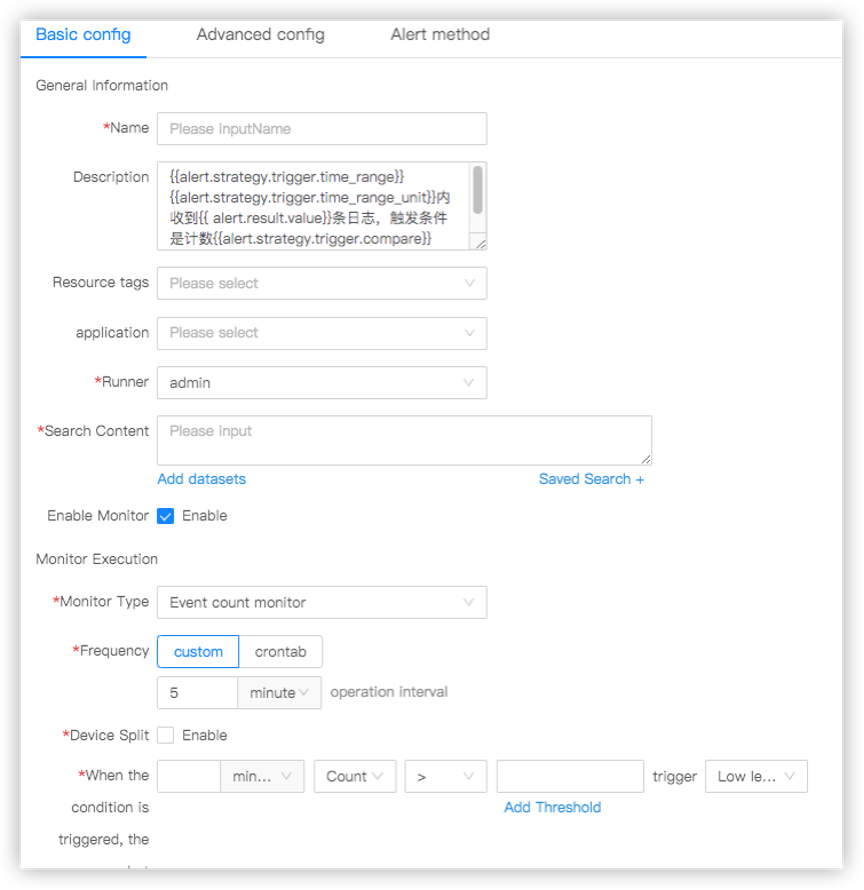
Результаты поиска можно запаковать в инцидент или в метрику, по которой настроить Alert-action. Выглядит это так:
Дальше метрики можно положить в плашки и получится что-то вот такое, тут пока не переведено, но если вы заинтересуетесь, то обещали тут же перевести, на английский, русский, казахский или какой скажете!
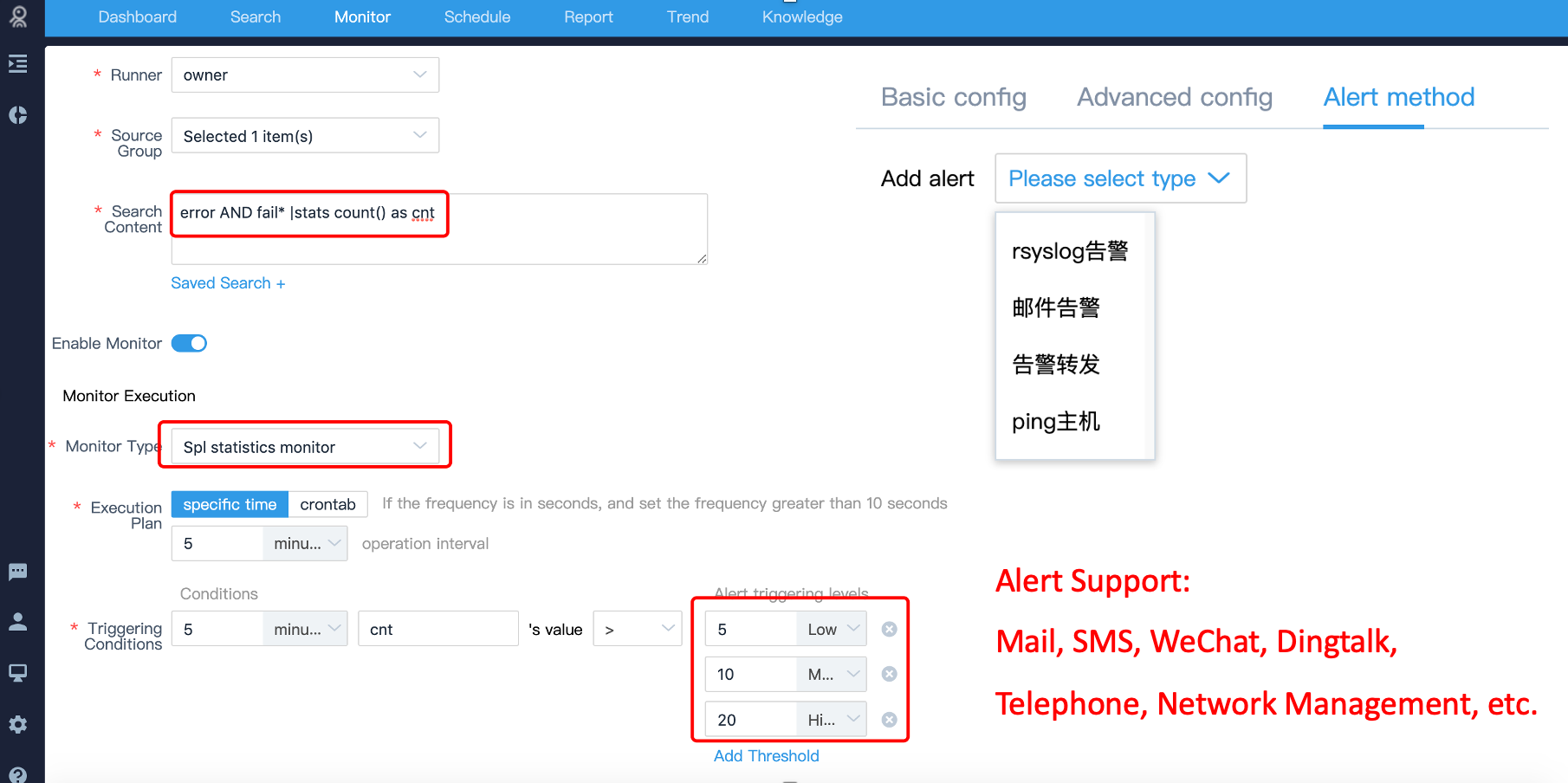
На срабатывания корреляционных правил настраиваются оповещения.
Визуализация: компонент YottaWeb
Это китайский Seachhead с различными визуализациями и пользовательским интерфейсом их создания/управления. Можно использовать API для настройки параметров доступа, управления ресурсами и внешней интеграции. Этот компонент кластеризуется, как и остальные блоки платформы.
Визуализировать можно начать непосредственно со строки результатов поиска, тут тоже прослеживается магия Splunk.
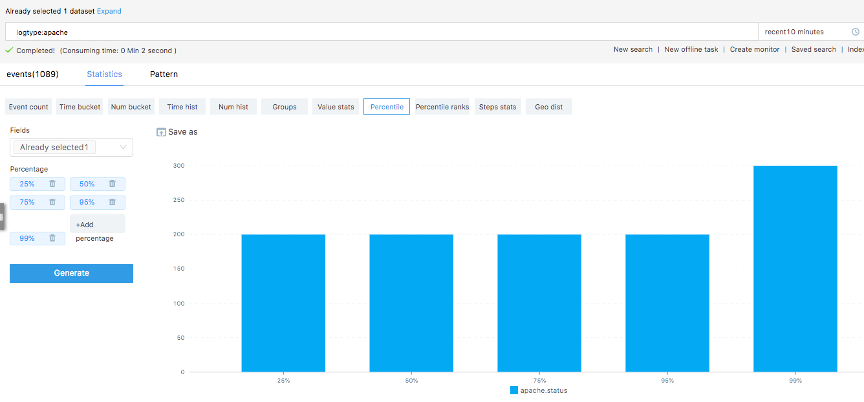
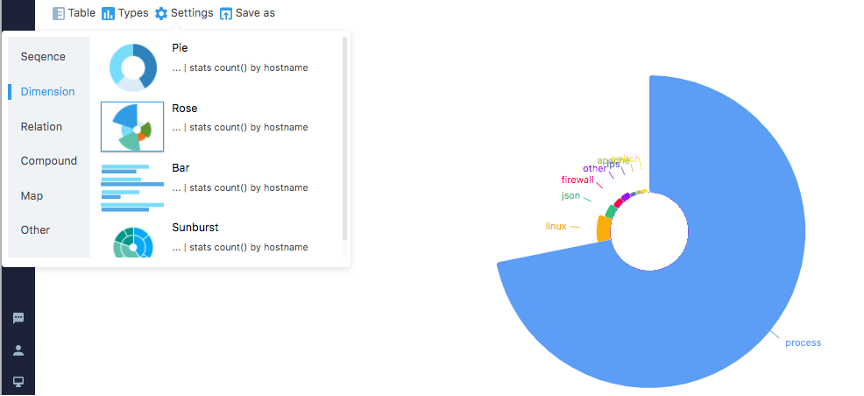
Ну а дальше крути, изменяй визуализацию и сохраняй на дашборд в удобном для тебя виде. Как это все в результате смотрится, дело вкуса. Тут, на наш взгляд, работу можно было бы продолжить, как в части компоновки визуальных витрин, так и по кастомизации отдельных виджетов. Посмотрим, если коллеги запросят консультацию, сможем им лучшие практики свои продемонстрировать, есть чем обогатить решение.
В тёмной теме примерно вот так может выглядеть центральная панель системы мониторинга.
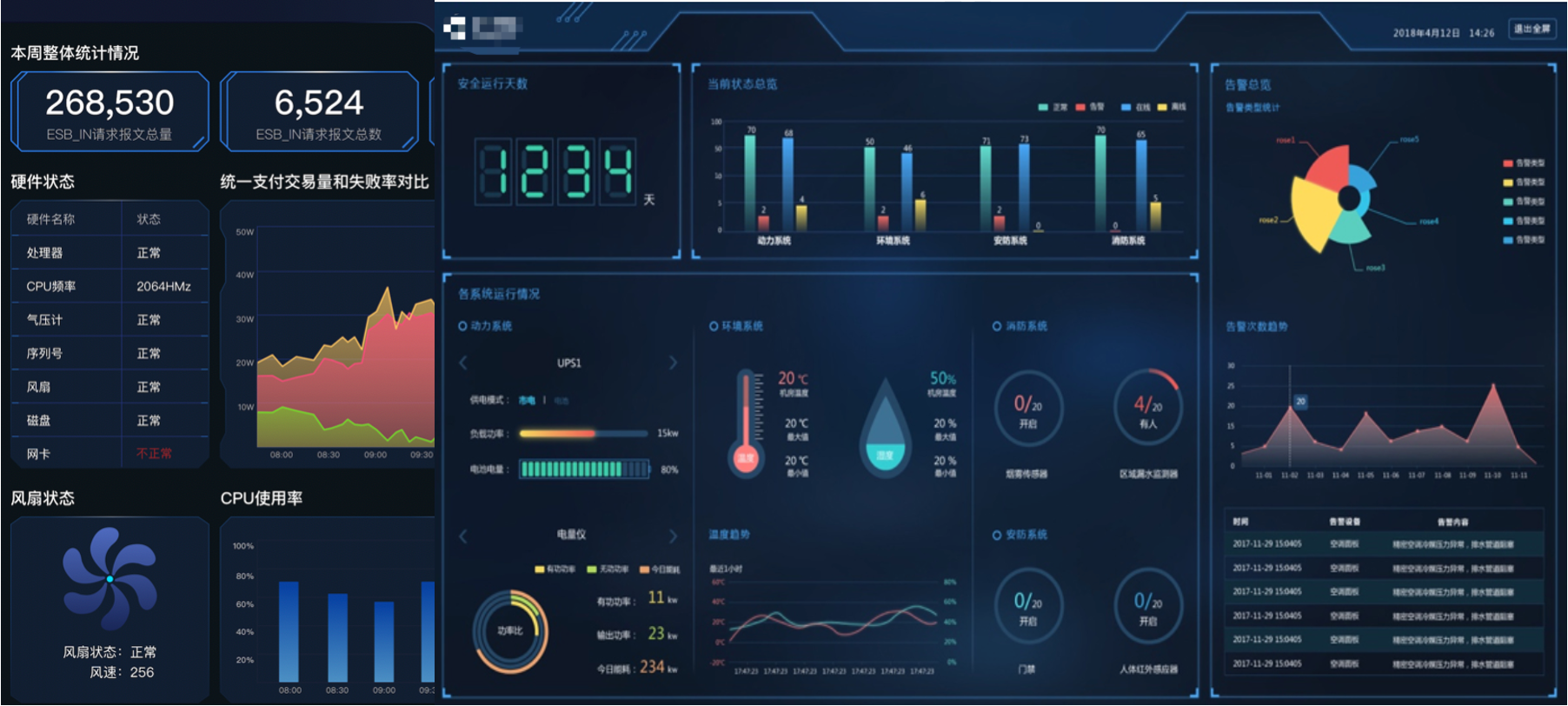
Можно настроить dill down на дашборде.
Algorithm service Analyzer, как аналог MLTK
В этот компонент вошли наработки по AI (он же ML), а также автоматизирующие подсчет KPI и метрик инструменты (KPIAnalyzer и LogAnalyzer соответственно). Эти инструменты для работы дергают спрятанный внутри Spark. В части реализованных AI-пресетов из коробки идет 20 моделей машинного обучения, которые можно дергать из синтаксиса поисковых запросов, как нам сказали. Сами не дергали.
Централизованная консоль управления (Maintenance and management Manager)
Раз речь про кластер, то вот с помощью этой консоли предлагается всем хозяйством рулить: централизованно развертывать, управлять конфигурацией, следить за производительностью, обновлять компоненты. Внутри для хранения служебных данных примеряется InfluxDB.
Приложения с бизнес-логикой
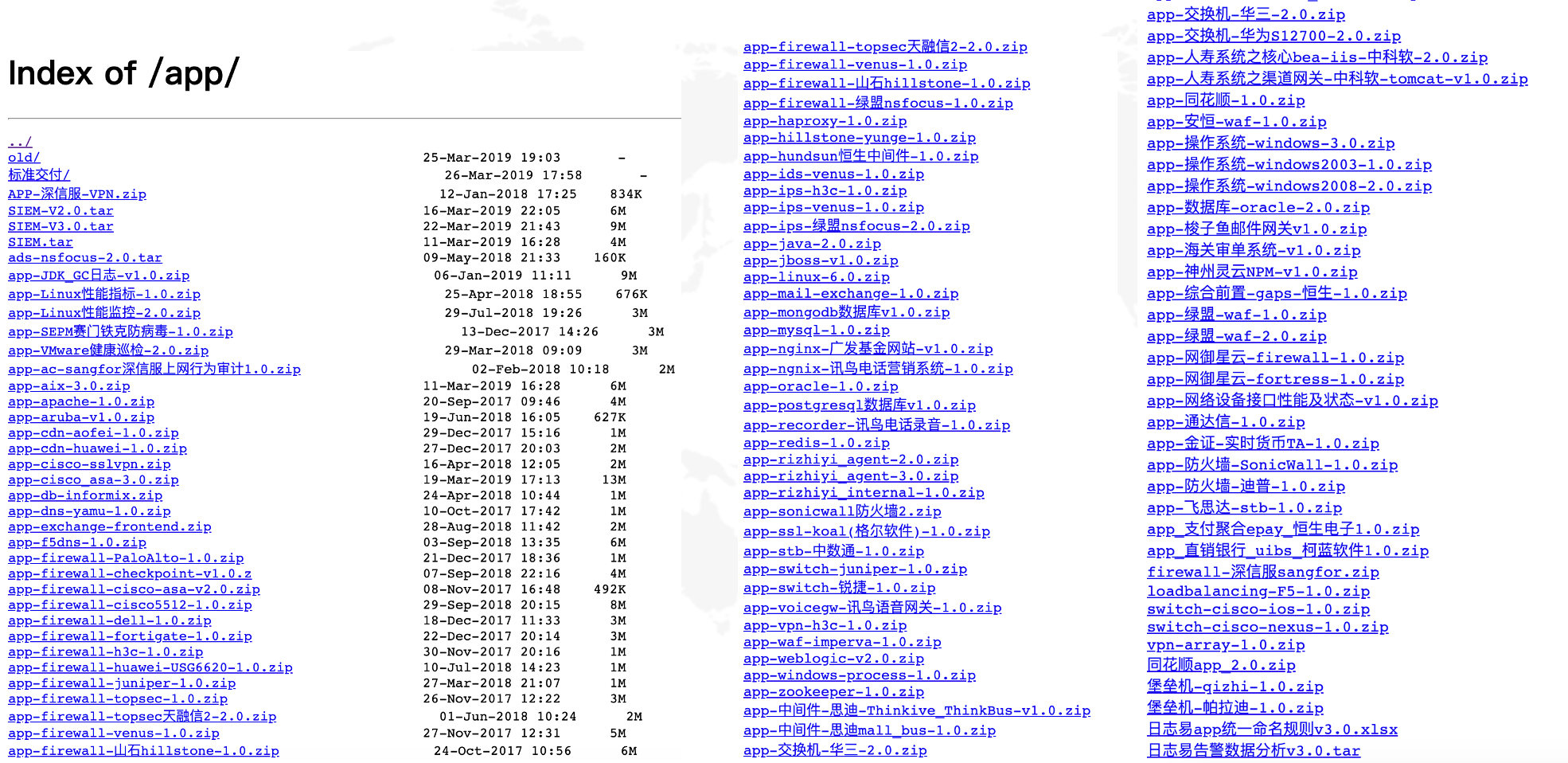
Приложения оформлены в экспортируемые/импортируемые файлы, и их, судя по следующей картинке, приличное количество.
Приложение с функциями SIEM
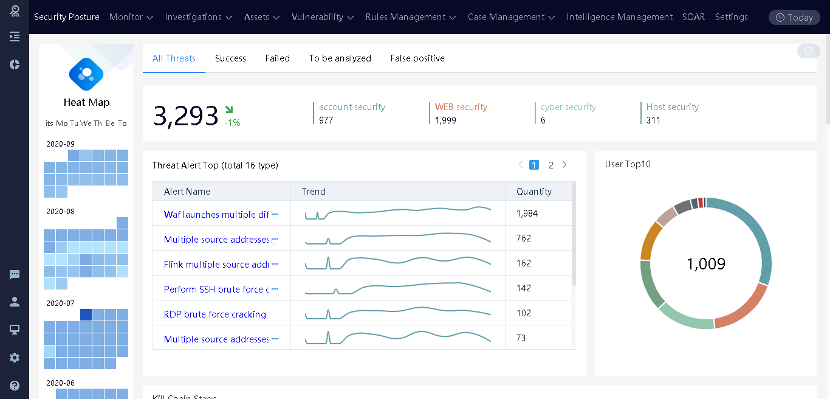
Называется приложение Rizhiyi security event management platform. Позволяет выявлять инциденты, проводить расследования, управлять активами, управлять уязвимостями, конфигурировать компоненты, обладает собственным планировщиком заданий.
Общая картинка с тепловой картой выявленных инцидентов выглядит так:
География атак на карте:
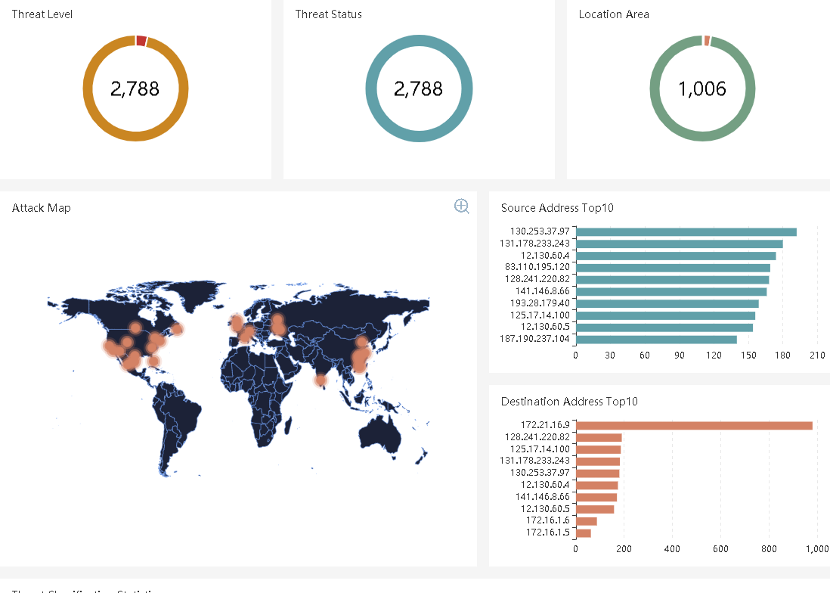
Есть собственный NTA.
Анализируют сценарии атак так:
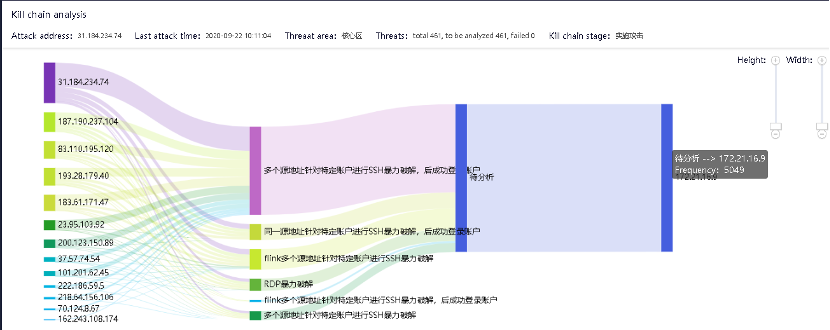
Для расследований формируют timelime c артефактами атаки.
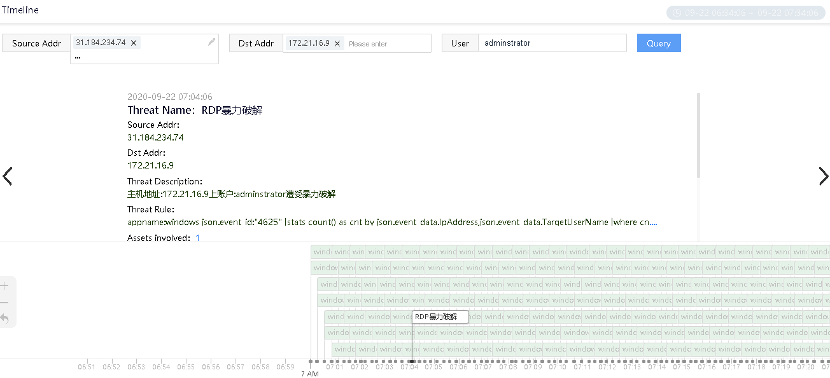
Строят интерактивную карту по вовлеченным в атаку активам.
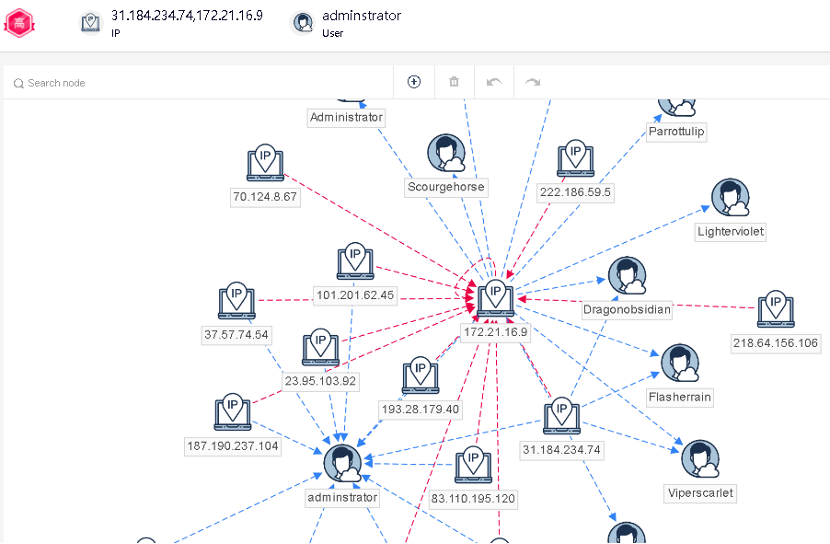
Систематизируют информацию об активах в едином центре.
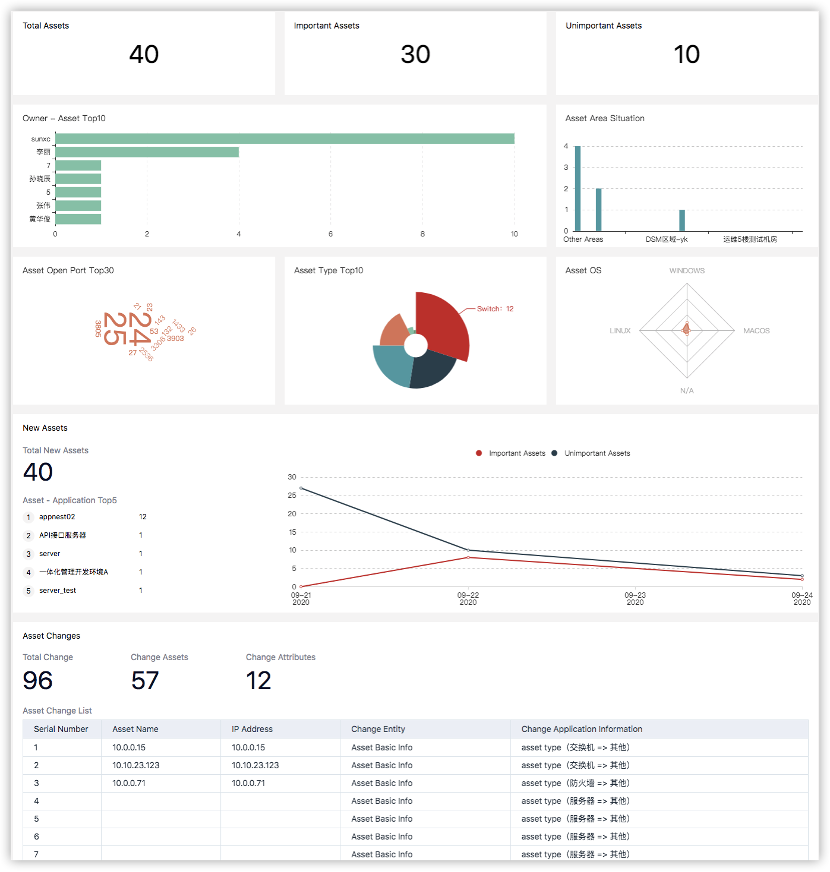
По каждому активу дают расширенную (на текущий момент китайскую) аналитику:
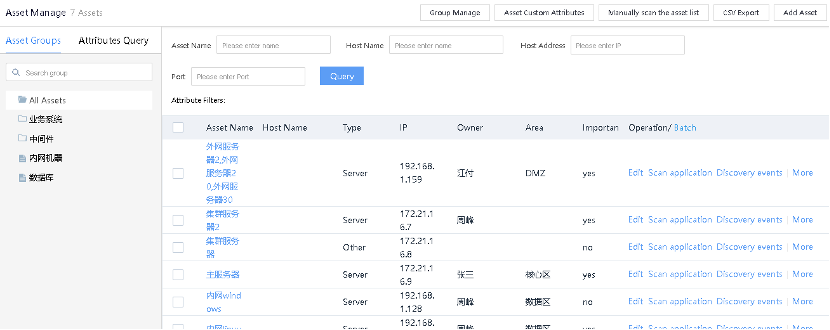
Запускают автоматизированное сканирование сети на предмет поиска новых хостов и позволяют импортировать csv с результатами сканирования внешних сканеров.
Вместо заключения
Товарищи создали платформу и богато обогатили её приложениями прикладного уровня, как для ИБ, так и для ИТ, и да, для анализа бизнес-процессов. Очень уверенно чувствуют себя на китайском рынке, особенно в финансовом секторе, где являются де-факто стандартом мониторинга. Готовы переводиться и “пенетрировать” российский рынок. Кто теперь скажет, что китайский рынок закрыт и не хочет экспортировать свой проприетарный софт в РФ, тот не прав. Хотят и, думаем, могут. Если вам нра, то можем организовать вам “приземление”. Мы за добрую и честную конкуренцию, сами у коллег подсмотрели и ряд интересных моментов для обогащения нашего Smart Monitor. Надеемся, вы не зря потратили несколько минут и узнали о интересной платформе, которая успешно конкурирует со Splunk и happy от этого!