Обзор новых возможностей Splunk 6.2
В октябре компания Splunk выпустила новую версию своей платформы Splunk Enterprise 6.2. В этой статье представлен краткий обзор ключевых нововведений этой версии.
Обнаружение шаблонов событий
События, представляющие из себя результаты выполнения поисковых запросов, могут быть автоматически сгруппированы с использованием определенных шаблонов (event patterns). События, сгруппированные таким образом, имеют определенные характеристики, и, как правило, могут быть отобраны специфическим поисковым запросом. Каждый из обнаруженных шаблонов объединяет события со схожей структурой данных. Анализ на основе шаблонов хорош тем, что в автоматическом режиме показывает наиболее распространенные типы событий в результатах поискового запроса. Кроме того, имеется возможность создания оповещения на основе шаблонов: например, оповещение в случае изменения частоты возникновения событий определенной структуры данных.
Рассмотрим пример использования инструмента Patterns, приведенного в документации Splunk.
Мы запускаем поисковый запрос «sourcetype=cisco_esa». Запрос возвращает нам 55 518 событий.
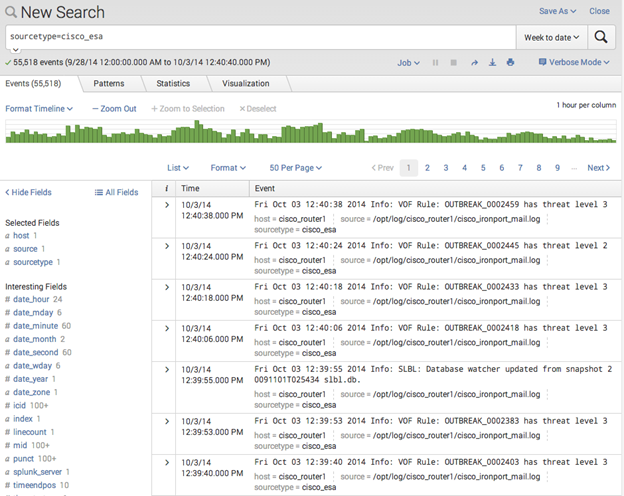
Большинство событий соответствуют двум шаблонам: уведомление об уровне угрозы и уведомление о том, что обновился database watcher.
Для того, чтобы просмотреть все шаблоны в выбранном наборе данных, необходимо перейти на вкладку Patterns.
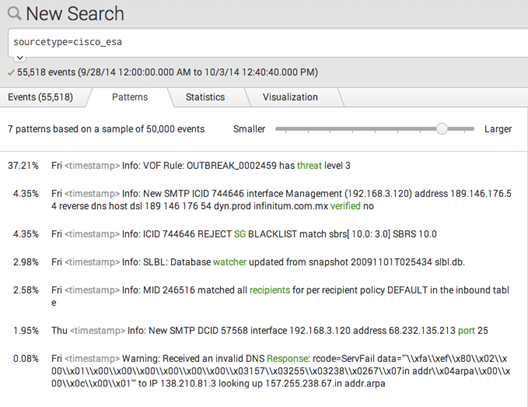
Splunk обнаружил 7 шаблонов. Шаблон сообщения об уровне угрозы является наиболее распространенным. Группы событий, соответствующие некоторым шаблонам, очень редко встречаются, и обнаружить их на вкладке Events бывает достаточно проблематично. Инструмент Patterns позволяет достаточно легко выявить такие шаблоны и сохранить их в качестве отдельного типа событий, который можно будет использовать в поисковых запросах.
Механизм обнаружения шаблонов в событиях основывается на присутствии или отсутствии ключевых слов в тексте события. В примере выше события, соответствующие шаблону сообщений об уровне угрозы, имеют ключевое слово «threat». Оно выделено зеленым. Поисковый запрос, который вернет события, удовлетворяющие данному шаблону, следующий: «sourcetype=cisco_esa threat».
В случае, если Splunk обнаружил слишком большое или слишком маленькое количество шаблонов, можно воспользоваться ползунком для увеличения или уменьшения степени детализации результатов:

Передвигая ползунок по шкале можно увеличить или уменьшить количество шаблонов событий, которые найдет алгоритм.
В случае передвижения ползунка в сторону Larger, Splunk пытается объединять найденные шаблоны в группы и собрать внутри каждой группы более широкий спектр событий. Эта часть шкалы ориентирована на поиск общих закономерностей.
В случае передвижения ползунка в сторону Smaller, увеличивается степень детализации результатов, соответственно, увеличивается количество шаблонов. Эта часть шкалы предназначена для определения деталей – менее существенных закономерностей с большей степенью детализации.
Кликнув на определенный шаблон на вкладке Patterns можно просмотреть детальную информацию:
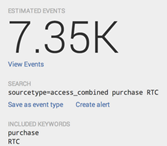
Здесь отображается примерное число событий из базового поискового запроса, соответствующих выбранному шаблону. Также мы видим поисковый запрос, на котором основывается данный шаблон, ключевые слова. Имеется возможность сохранить шаблон как тип события или создать оповещение (например, в случае, если частота возникновения событий по данному шаблону увеличилась или уменьшилась).
Instant Pivot: Работа с инструментом Pivot без заранее созданной модели данных
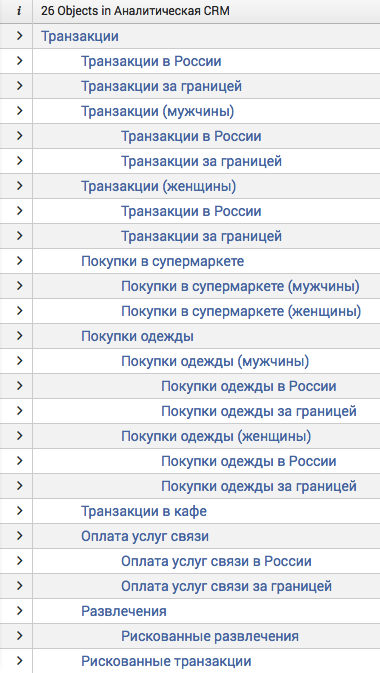
Инструмент Pivot позволяет любому пользователю создавать функциональные отчеты, не владея языком поисковых запросов платформы Splunk. Ранее для получения возможности использования Pivot для создания отчетов, пользователю необходимо было предварительно создать модель данных. Модель данных представляет из себя набор взаимосвязанных данных, представленных в виде иерархической структуры. Рассмотрим пример модели данных по транзакциям пользователей по банковским картам из приложения Smart Bank:
Чтобы создать отчет, пользователю необходимо выбрать элемент модели данных, на основе которого он хотел бы произвести анализ информации. Далее нужно в визуальном редакторе Pivot установить необходимые фильтры по значениям полей и форму визуализации данных. Например, на рисунке ниже представлен отчет по количеству покупок женщин в возрасте до 25 лет в магазинах одежды в различных городах мира.
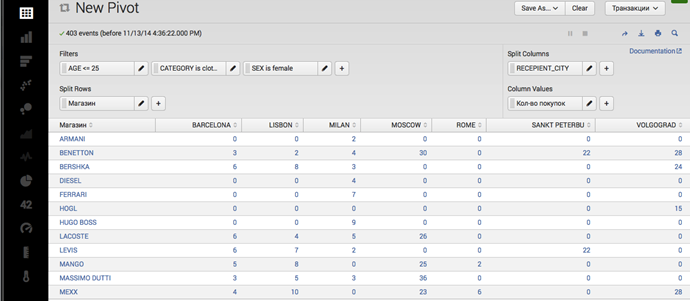
Полученный отчет может быть сохранен для дальнейшего использования.
Появившийся в версии Splunk Enterprise 6.2 инструмент Instant Pivot позволяет представить любой поисковый запрос в инструменте Pivot, не требуя предварительного создания модели данных. Модель данных будет сформирована автоматически на основе введенного пользователем поискового запроса.
Нам необходимо ввести поисковый запрос, на основе которого мы хотим построить отчет в Pivot, и на вкладке «Visualization» кликнуть на кнопку «Pivot».
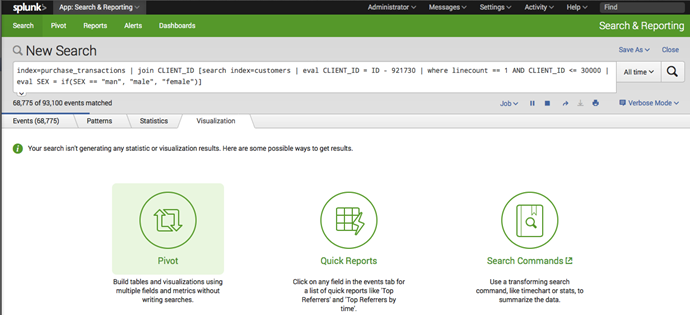
Автоматически будет построена модель данных на основе поискового запроса, и мы сможем построить в Pivot необходимый нам отчет. Сгенерированная модель данных может быть сохранена для дальнейшего использования и модификации.
Таким образом, использование инструмента Instant Pivot позволяет значительно сократить время разработки базовой модели данных для последующего построения отчетности по любому объему данных.
Search head clustering
Кластеризация Search Head обеспечивает повышение доступности, путем репликации пользовательских конфигурационных параметров, информационных панелей и отчетов между Search Head. Пользователи могут одинаково работать с любым из элементов кластера.
Ключевые возможности:
- автоматическая синхронизация файлов между Search Head;
- узлы Search Head могут быть добавлены в кластер или удалены без выключения кластера;
- централизованное управление узлами кластера;
- нет единой точки отказа в архитектуре Splunk.
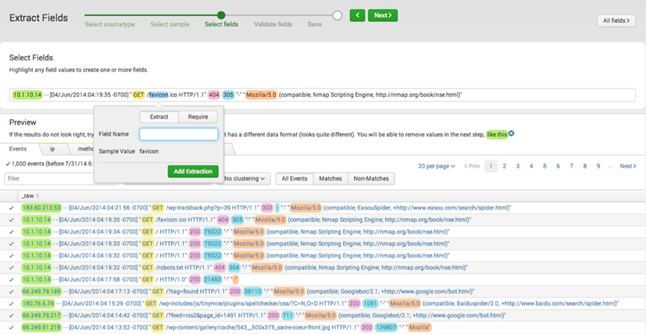
Инструмент Advanced Field Extractor
В Splunk 6.2 упростился механизм извлечения полей из событий пользователем с помощью визуального интерфейса Advanced Field Extractor (AFX). AFX заменил существующий инструмент визуального извлечения полей из событий. Теперь появилась возможность извлекать одновременно несколько полей, фильтровать события во время извлечения (для повышения точности и эффективности). Кроме того, AFX предоставляет несколько методов обнаружения ложных срабатываний при извлечении полей, чтобы проверить корректность и повысить точность извлечения полей (для этого новым извлеченным полям присваиваются цвета и лог визуально раскрашивается).
Дизайн Home Page
В Splunk 6.2 изменился дизайн главной станицы. Для того, чтобы предоставить пользователям более быстрый доступ к данным и приложениям, Splunk позволяет поместить на главную страницу любую существующую информационную панель.
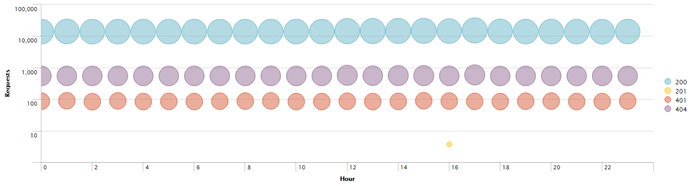
Новый тип диаграмм: Bubble Chart
Добавился новый тип диаграмм: Bubble Chart. Данный тип диаграммы позволяет визуализировать ваши данные в трех измерениях. На рисунке ниже отражена информация о подключениях к web-сайту за сутки. На оси Y расположена временная шкала, на оси X – количество подключений. Цвет «пузыря» отображает разбиение по коду ответа на http-запрос. Диаметр «пузыря» показывает суммарное количество переданных байт по всем запросам с определенным кодом ответа за соответствующий период времени.
Ускорение построения собственных информационных интерфейсов путем использования заранее подготовленных панелей
Процесс создания собственных интерфейсов ускоряется путем использования заранее заготовленных панелей, упакованных в приложения. Т.е. теперь пользователь может непосредственно в режиме редактирования собственного интерфейса выбрать панель с графиком, диаграммой или таблицей из набора панелей, уже имеющихся в различных приложениях, и добавить панель в свой интерфейс.
Заключение
Каждая новая версия Splunk привносит значительное количество усовершенствований и новшеств, делая работу с платформой более простой, удобной и приятной для пользователей, архитекторов и разработчиков. Не исключение и версия 6.2. Из наиболее интересных нововведений можно отметить появление возможности построения кластера для компонентов Search Head, что исключает единственное узкое место в архитектуре. Также довольно интересен инструмент Patterns, который позволяет ускорить процесс исследования групп событий для новых источников данных.