Результаты конференции «Большие данные 2016»
 Конференция «Большие данные 2016», организованная CNews, состоялась 10 марта. На фото я рассказываю очередную рыбацкую историю про «вооот такие вот объемы анализируемых данных» ))
Конференция «Большие данные 2016», организованная CNews, состоялась 10 марта. На фото я рассказываю очередную рыбацкую историю про «вооот такие вот объемы анализируемых данных» ))
Пришло около 100 заинтересованных в Big Data участников из разных отраслей бизнеса.
От нашей компании я выступил с докладом «Практика извлечения пользы из машинных данных».
В ходе выступления решили организовать интерактивное голосование. Мы уже несколько раз на мероприятиях использовали интересный инструмент взаимодействия с аудиторией, который для себя назвали «шейкером».
Работает он так: участник мероприятия с мобильного телефона заходит на заранее подготовленную страничку в Интернете, где ему предлагается выбрать один из вариантов и проголосовать. Собственно, шейкером инструмент назван потому, что позволяет не просто выразить мнение, выбрав один из пунктов, но и добавить эмоциональную окраску своего выбора; для этого достаточно встряхнуть свой телефон. От интенсивности встряски зависит вес голоса в рамках голосования.
В целом, инструмент направлен на то, чтобы увеличить вовлеченность участников в мероприятие и немного их встряхнуть. Ну и конечно, же, оперативно собрать их мнения без заполнения скучных анкет и специализированных приложений. Достаточно просто на 30 секунд отвлечься от чтения почты и Facebook.
Первый вопрос, который нас интересовал, звучал так: «В какой 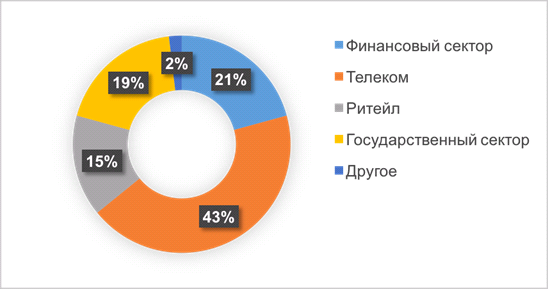 области Big Data действительно приносит практическую пользу?».
области Big Data действительно приносит практическую пользу?».
Результаты голосования были достаточно интересными. Если честно, я ожидал увидеть в качестве лидеров по извлечению пользы финансовый сектор. Тем более, что его представителей было на конференции больше всего.
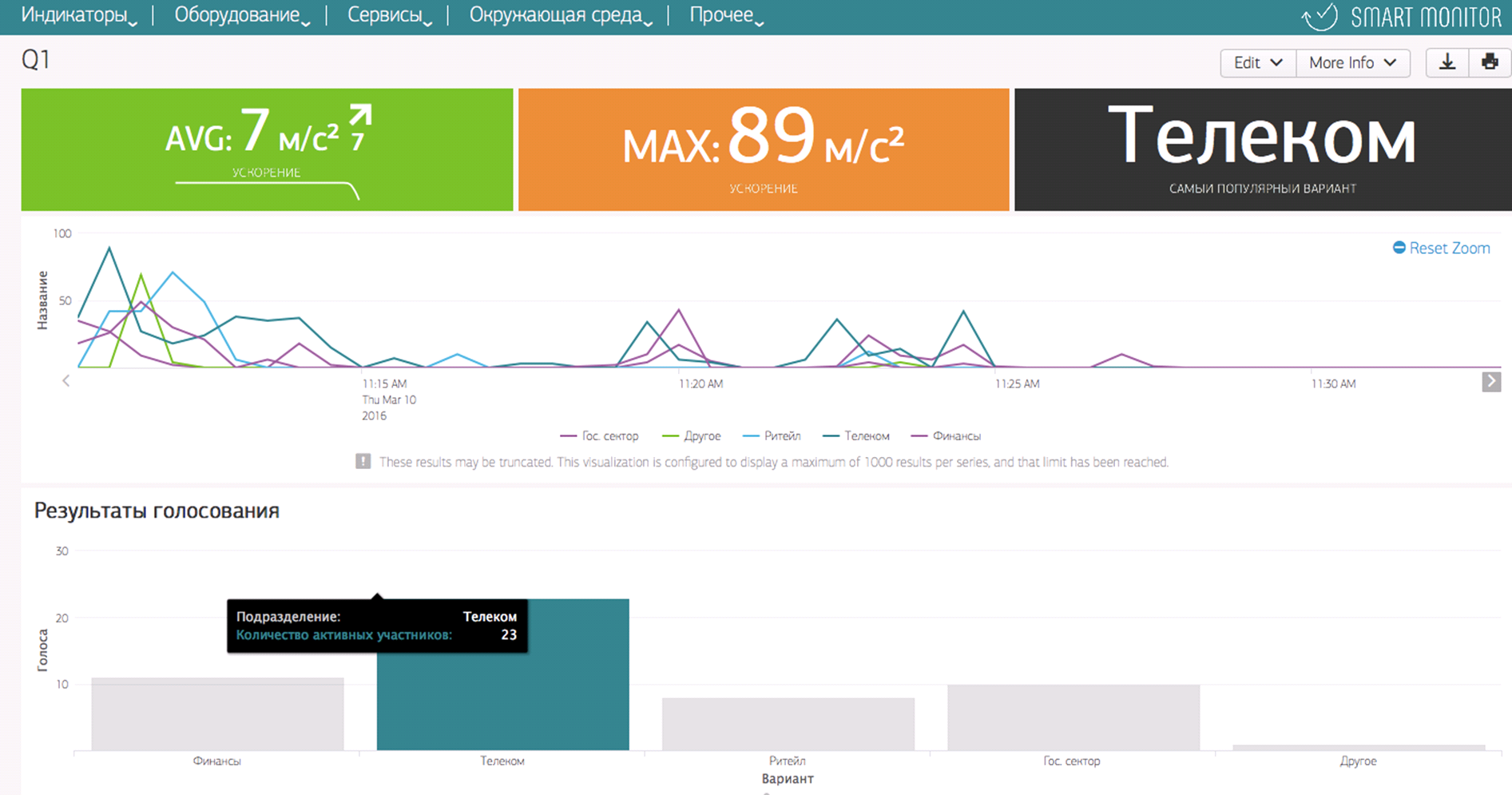
Активность голосующих мы сразу фиксировали в своем решении по комплексному мониторингу, Smart Monitor.
В режиме реального времени мы выявляли наиболее популярный ответ, группировали голосующих и отслеживали активность групп с построением динамики голосования на временной шкале, строили итоговое распределение голосов.
Дальше поговорили о практических сферах применения машинных данных и о вариантах технической реализации. Наверно, вы знаете, про что я говорил ). Вот тут презентация, можно посмотреть. Я там перекрасил один рисунок, который активно бродил по Интернету несколько недель назад ).
Достаточно живо публика отреагировала на доклад Кириллов Александра (Руководитель направления монетизации данных, Data-Centric Alliance). Мне запомнился продукт IPPROFILE – система идентификаторов пользователя, которая позволяет накапливать и связывать разнородные “локальные” идентификаторы вокруг “глобального” виртуального интегрального профиля, а также организовывать хранение профилей и обеспечивать быстрый доступ к привязанной поведенческой или иной информации. По факту, консолидируется профиль Интернет-пользователя за счет коллекционирования cookies с великого множества сайтов, и последующим выявлением потребительских предпочтений, возраста, пола и других интересных подробностей. Это все подкреплено «сырыми данными» о посещенных сайтах и информацией из социальных сетей. В профиле собирается информация с разной степенью достоверности, можно отфильтровать факты, в которых уверенность почти 100%, можно «добавить огня» из непроверенных фактов.
База таких профилей потом продается всем заинтересованным. Есть и другие сервисы: заказчик отправляет hash, взятый из идентифицирующих пользователя атрибутов (например, номер телефона и email), а ему в ответ отгружается профиль пользователя. Дальше эти данные можно использовать, как дополнительные факторы в рисковых моделях при выдаче кредита, для адресных рекламных предложений и другими эффективными способами. На вопрос про персональные данные ответ был простой – их тут нет. Про процедуру обогащения собранных ПДн после получения профилей Интернет-пользователей поговорить не успели, конференция быстро подошла к концу. Но, наверняка, все нормы соблюдены, в другое просто верить не хочется!
Интересно рассказывали коллеги из PROMT и Brand Analytics по поводу лингвистических анализаторов и исследования больших массивов текстовых данных.
Шаблыков Никита, Директор по продажам, PROMT, представил новый продукт своей компании – PROMT Analyser. Мы, как участники конференции, получили бесплатный доступ к тестовому контуру, которым не преминули воспользоваться.
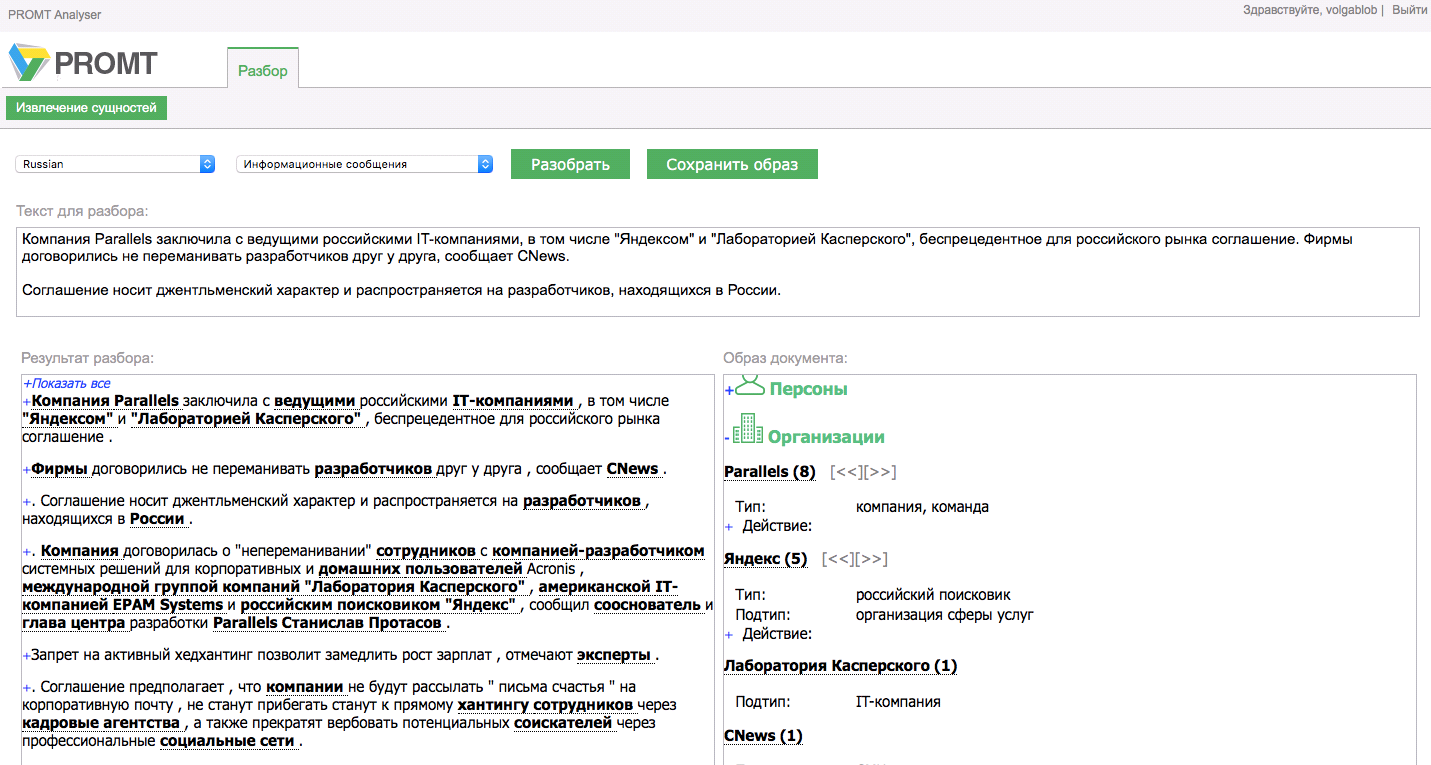
Действительно качественно выявляет сущности (персоны, организации, географические названия) и факты из текстовых блоков, и выделяет действия, связанные с этими сущностями. Понимает контекст, и может добавить к сущности факты на основании упоминания «он», этот» и подобных.
В целом ощущение очень похожее на первый SOC-Forum, где спорили о терминах: у каждого своя Big Data. А у некоторых даже Big Big, чтобы не перепутали!