Splunk и Tensorflow: поиск мошенника с помощью биометрического анализа поведения
Прошедший 2016 год стал еще одним годом устойчивого роста количества кибератак и годом существенных потерь от мошенничества во многих отраслях: от электронной коммерции и здравоохранения до финансового и промышленного сектора. Под удар попали также страховые компании и государственные учреждения.
Захваты пользовательских аккаунтов, кражи учетных данных, фальсифицирова нные онлайн-транзакции остаются основными методами мошенничества, которые уже многие годы наносят непоправимый финансовый урон и портят репутацию компаний. Более 50% успешных атак инициируются с использованием легитимных учетных данных.
нные онлайн-транзакции остаются основными методами мошенничества, которые уже многие годы наносят непоправимый финансовый урон и портят репутацию компаний. Более 50% успешных атак инициируются с использованием легитимных учетных данных.
Геолокация? Threat Intelligence Feeds? Распознавание устройств? Корреляция IP-адресов? Злоумышленники прекрасно знают обо всех этих методах обнаружения.
Мошенники становятся все более изощренными. В попытках обойти самые сложные системы обнаружения мошенничества и ввести в заблуждение экспертов по безопасности они могут за нескольких минут скрыть свое местоположение, воспользовавшись облаками дешевых виртуальных машин по всему миру или использовать специализированные средства подмены идентификационных данных устройств. Выявление злоумышленника или подозрительной транзакции по аномалиям в IP-адресах, идентификаторах компьютерных устройств или полях User-Agent становится все более сложной задачей.
Для построения более эффективных средств защиты нам требуется рассмотреть возможность обогащения традиционных источников данных информацией, которая отражает уникальные и сложные по своей структуре шаблоны поведения человека по ту сторону экрана. Именно так мы найдем то, что мошенники и киберпреступники не смогут украсть или подделать.
 Люди работают с компьютерными системами каждый по-своему, в соответствии со своими физическими и психологическими особенностями. То, как люди нажимают кнопки или вводят текст, как используют мышь или другие устройства ввода – все это сильно зависит от поведения человека, его привычек, уровня образования и знания системы.
Люди работают с компьютерными системами каждый по-своему, в соответствии со своими физическими и психологическими особенностями. То, как люди нажимают кнопки или вводят текст, как используют мышь или другие устройства ввода – все это сильно зависит от поведения человека, его привычек, уровня образования и знания системы.
Привычки и поведение очень сложно изменить, и если мы сможем идентифицировать добросовестного пользователя по его типичным поведенческим шаблонам, мы сможем обнаруживать аномалии на совершенно новом уровне. То же самое и с мошенниками – способность идентифицировать и оценить поведенческие шаблоны киберпреступников позволит нам раскрыть и нейтрализовать угрозы, которые невозможно обнаружить с помощью других средств.
Вопрос в том, можем ли мы распознавать пользователей (или классы пользователей) по каким-либо индивидуальным особенностям использования ими мыши или клавиатуры? Поведенческая биометрия – это область исследований, связанная с выявлением измеримых поведенческих шаблонов в человеческой деятельности, позволяющих однозначно идентифицировать кого-либо.
Эта статья расскажет об одном из способов применения поведенческой биометрии для решения задач безопасности. В качестве инструмента применяется платформа Splunk, дополненная средствами глубокого обучения (Deep Learning Framework).
Попытки обнаружить и классифицировать биометрические шаблоны предпринимались рядом отраслевых игроков. Давайте рассмотрим задачу сопоставления пользователя с его действиями компьютерной мышью. Традиционная система обнаружений выполняет сложные действия по извлечению признаков, измерению и нормализации данных. Для каждого события передвижения курсора система использует искусственное сглаживание траектории, фиксирует траекторию движения, измеряя в разных точках скорость, ускорение, кривизну, относительные расстояния, точки изменения траектории движения и т. д.
После такой тяжелой предварительной обработки к извлеченным признакам применяются традиционные методы машинного обучения. Модель обучается, затем осуществляется прогнозирование.
Ограничение такого подхода заключается в том, что сложность задачи искусственно сводится к подмножеству вычисленных признаков, а остальные данные игнорируются. Это почти гарантирует, что более сложные, тонкие, но вместе с тем и более персонализированные шаблоны поведения, присутствующие в сырых данных, не будут выявлены.
Для обнаружения, извлечения и распознавания бесконечно сложных шаблонов, которые могут присутствовать в сундучке с кладом пользовательских поведенческих данных, нам необходимо исследовать полные, нефильтрованные наборы данных с помощью методик и техник, выходящих за рамки традиционных алгоритмов, основанных на подмножестве созданных признаков.
Но как мы получим доступ к детализированным наборам данных, представляющим пользовательские действия? Точно так же, как и с любым другим источником данных – довольно легко направить точные и подробные данные об активности пользовательского устройства ввода прямо в Splunk. Спасибо нашему талантливому разработчику Oleg Izmerly – этот исходный код как раз демонстрирует, как можно это сделать.
Зная, что каждое движение мыши генерирует координаты X и Y указателя, а также временную метку, мы можем собрать эти данные и отправить в Splunk для обогащения традиционных источников данных, таких как маршруты перемещения посетителя по сайту (clickstream), журналы событий веб-сервера (web) и сервера приложений (application). Таким образом, данные об активности пользователя в сессии будут содержать информацию о потенциально уникальных шаблонах поведения.
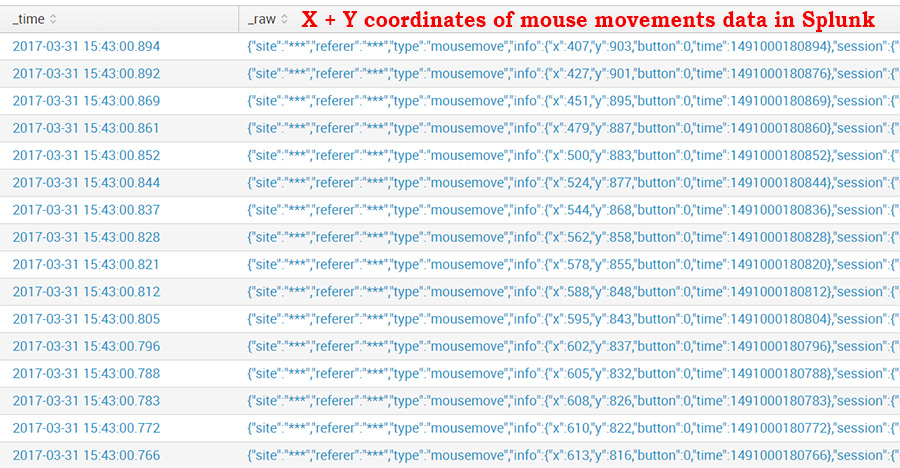
Действия мышью порождают события каждые 5-10 миллисекунд. За время одной пользовательской сессии может генерироваться порядка 5 000 – 10 000 событий для одной страницы. Много данных для анализа – это хорошо!
Для решения задачи мы решили объединить и преобразовать данные об активности мыши в цветные изображения. В конце концов, курсор мыши всегда движется по плоской двухмерной поверхности, и это естественно – преобразовать этот набор событий в единое изображение, к тому же без потери деталей. Одно изображение может представлять тысячи точек активности мыши. Мы разработали специальный высококонтрастный алгоритм цветового кодирования для согласованного представления направления, скорости и ускорения движений курсора. Это, к примеру, помогло нам выяснить разницу в модели поведения между левшами и правшами. Нажатия кнопок мыши изображены большими цветными кругами, движения типа “щелчок+перетаскивание” нарисованы более толстыми линиями. Такой подход позволил нам закодировать не только линии траекторий, но также визуально представить многомерную динамику человеческого поведения во всевозможных подробностях, готовую к анализу и классификации.
После создания высококонтрастных изображений м ы решили использовать технику Deep Learning, в которой все изображения обрабатываются специальными многослойными алгоритмами распознавания образов. Они предназначены для обнаружения всевозможных шаблонов, которые могут содержаться в изображении.
ы решили использовать технику Deep Learning, в которой все изображения обрабатываются специальными многослойными алгоритмами распознавания образов. Они предназначены для обнаружения всевозможных шаблонов, которые могут содержаться в изображении.
Deep Learning (глубокое обучение) – это класс алгоритмов машинного обучения, который использует многослойную систему нелинейных фильтров для извлечения признаков с преобразованиями.
Подмножество алгоритмов Convolutional Neural Networks оказалось очень эффективным для задач распознавания образов. Эти алгоритмы могут автоматически обнаруживать признаки, фигуры и шаблоны, важные для поставленной задачи классификации пользователей. При работе с очень сложными, неизвестными схемами мошенничествами и паттернами атак, такой подход имеет огромное преимущество по сравнению с ручным созданием признаков.
Для построении архитектуры нейронной сети были выбраны Deep Learning framework TensorFlow (с открытым исходным кодом) и высокоуровневая библиотека Deep Learning: Keras.
Keras позволяет реализовать полное распознавание образов с применением Deep Learning в 50-100 строках кода на Python. Благодаря прекрасным возможностям абстракции, Keras позволяет использовать другие Deep Learning фреймворки, такие как Theano, с очень небольшими изменениями в коде.
Мы использовали недорогую (~$350 на момент написания статьи) видеокарту среднего уровня с 6 GB памяти GPU в качестве аппаратного ускорителя для полного обучения сети Deep Learning на изображениях с траекториями движения мыши. Использование GPU для matrix-intense вычислений помогает ускорить процесс обучения в 10-100 раз, по сравнению с использованием только CPU.
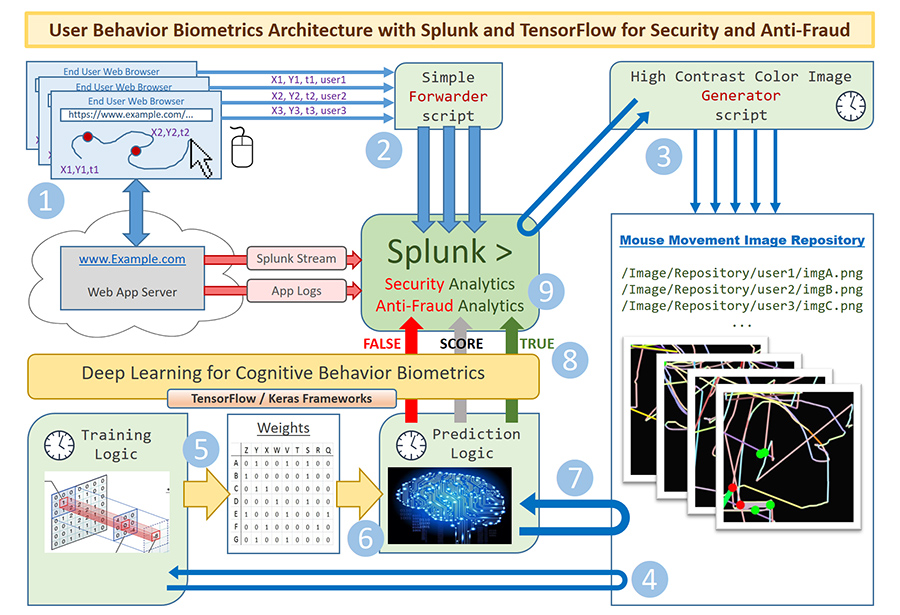
Источником для вычислений служил живой поток данных от реальных посетителей web-портала с финансовой информацией. После настройки описанной выше схемы получения данных в Splunk поступал поток событий активности мыши от каждого посетителя портала. Простой скрипт на Python запускался по расписанию, получал данные об активности мыши из Splunk через API и генерировал несколько тысяч изображений, визуализирующих движения мыши.
Данные готовы для анализа и классификации посетителей!
Создание группового профиля
Первой задачей для нас стало доказательство того, что сеть Deep Learning может быть обучена для распознавания двух категорий пользователей по движениям мыши при посещении одних и тех же страниц: постоянные клиенты портала финансовой информации и новички.
Мы исходили из гипотезы, что модель поведения людей, которые впервые посетили портал, отличается от тех, кто хорошо с ним знаком. «Новичку» необходимо потратить некоторое время на изучение, чтобы понять структуру портала. При этом модель активности мыши в процессе изучения может отличаться от модели активности мыши постоянных клиентов, чьи действия по поиску и получению доступа к необходимой им информации на портале в общем случае оказываются более эффективными.
Выбранная нами архитектура нейронной сети напоминает успешную архитектуру VGG16 для распознавания образов. В ходе реализации решения архитектура VGG16 была дополнительно оптимизирована для учета особенностей набора ненатуральных изображений, а также для ограниченного размера нашего набора данных.
На входе мы имели 2000 изображений для обучения и 800 для проверки (1000 + 400 для каждой категории пользователей). Потребовалось около двух минут обучения нейронной сети для достижения точности проверки около 81%:
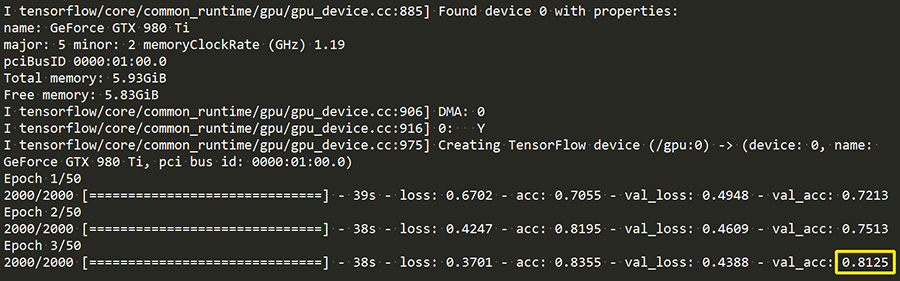
Это значит, что предварительно обученная система, основанная на этой архитектуре нейронной сети, сможет отличить постоянного клиента от нового с точностью более 80% при обработке данных об активности устройства ввода, которые она видит впервые. Это весьма существенно для обнаружении мошенничества и угроз в сценариях, где «чужаки» утверждают, что являются легитимными пользователями.
В итоге мы имеем архитектуру нейронной сети, подходящую для решения задачи поведенческой биометрии по разделению пользователей на разные категории путем анализа движений мышью.
Создание индивидуального профиля
Вторая задача была более интересной. Мы хотели определить, насколько подходит метод Deep Learning для распознавании конкретного пользователя на путем анализа использования им мыши.
Мы усложнили задачу, чтобы сделать ее более реалистичной:
- Размер выборки данных для этой задачи очень мал: у нас есть всего лишь 360 (по 180 + 180 на каждую категорию пользователей) изображений для тренировки + 180 (по 90 на категорию) изображения для проверки. В мире Deep Learning – это очень скромный набор данных.
- У нас есть один набор из 180 тренировочных изображений, представляющих активность мыши определенного зарегистрированного на портале пользователя.
- Оставшийся набор из 180 изображений, сформирован на основе активности других пользователей, имеющих следующие свойства:
- “Другие” – также пользователи портала;
- “Другие” ведут себя на портале похожим образом: посещают одни и те же разделы, совершают одни и те же действия;
- “Другие” используют устройства, аналогичные по размеру тем, с которых посещает портал первый пользователь – это значит, что движения мышью у них были очень близки по характеру к движениям мыши первого пользователя.
И вот в этих условиях нашей нейронной сети была поставлена очень тяжелая задача по распознаванию конкретного пользователя только на основании анализа движений мыши после тренировки на очень небольшом наборе данных.
Нам пришлось еще больше модифицировать архитектуру нашей нейронной сети, настроив ее так, чтобы обучение на очень небольшой выборке данных прошло стабильно и без необходимости к переобучению.
Мы все так же использовали концепции архитектуры свёрточной нейронной сети VGG16, однако в обновленной сети стало больше слоев для возможности выявления более сложных паттернов, плюс добавили ряд мер для значительного сокращения итераций переобучения.
Такая модифицированная нейронная сеть потребовала больше периодов обучения для получения приемлемых результатов:

После обучения по этому сценарию мы смогли достичь точности распознавания конкретного пользователя по движениям мыши в 78% по данным, попавших в систему впервые.
Чтобы получить эти результаты, сети потребовалось 3 минуты на обучение. Поскольку у нас была небольшая выборка, наблюдались «скачкообразные» результаты промежуточных итераций, но этого стоило ожидать. Сбор большего количества образцов данных позволит улучшить полученные результаты.
Подведение итогов и потенциал использования биометрии:
- Мы можем увеличить возможности по обнаружению атакующих и соотносить легитимных пользователей или группы пользователей с их уникальными профилями поведения. Это обеспечивает уменьшение ложно-положительных и увеличение “истинно-отрицательных” срабатываний. Подход применим и для профилирования легитимных пользователей, что очень актуально для финансовых организаций и электронных магазинов.
- Мы можем уменьшить нашу зависимость от IP-адресов, идентификаторов устройств и браузеров, т. к. все они могут быть подделаны злоумышленниками.
- Мы можем улучшить наши возможности по выявлению сложных вредоносных программ, инструментов удаленного доступа и другого хакерского инструментария, включая методы деперсонификации.
- Даже без глубокого обучения можно выявлять факт отсутствия активности мыши, который может свидетельствовать о действиях бота или злоумышленника.
- Биометрические данные о поведении могут быть отправлены обратно в Splunk, для обогащения существующих профилей, что позволит лучше оценить риски.
- Используя Splunk, собирать данные биометрические поведенческие данные очень просто, а в комбинации с алгоритмами Deep Learning это дает большое преимущество при решении задач безопасности и борьбы с мошенничеством.
Информационный источник: Gleb Esman, Sr. Product Manager for Anti-Fraud Products at Splunk.