Splunk Discovery Day Moscow

Любой вопрос. Любые данные. Только Splunk!
В Москве 30 ноября проходит ежегодная конференция Splunk Discovery Day Moscow, организованная официальным дистрибьютором Splunk, компанией RRC.
Как всегда, программа очень насыщена и интересна. Выступят ключевые сотрудники Splunk на рынке России и СНГ, прозвучат самые интересные кейсы по применению Splunk от российских клиентов (Росгосстрах, Мегафон, MARS и др.).
Практикам предстоит выбрать: идти на мастер-классы или учавствовать в круглых столах.
Для себя мы выбрали так: проводить мастер-класс и модерировать круглый стол 🙂
14.30-15.30 Экспертный круглый стол
Итак, наш круглый стол. Называется:
Как поможет Splunk на различных уровнях зрелости ИБ в вашей организации?
Предлагаю обсудить вот какие вопросы:
- Зачем вам SOC и готовы ли вы к нему?
- “Быстрые победы” в ИБ на Splunk. Как определить к чему вы готовы сейчас и не заниматься прожектерством.
- Последовательное развитие ИБ на базе микро-проектов (кейсов) на Splunk.
- Что делать своими силами, а что лучше отдать на аутсорсинг?
В качестве предварительного “вброса шайбы” по третьему вопросу, привожу картинку, которую предлагаю обсудить. В свое время её в Facebook живо обсудили с подачи Алексея Лукацкого.
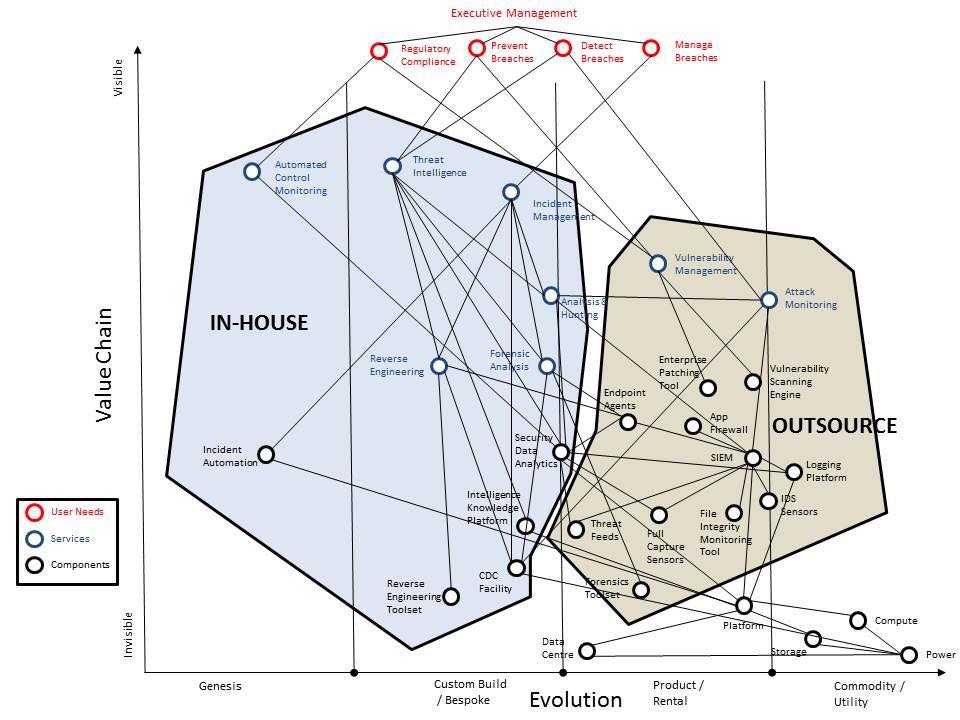
Кажется, что места на него уже кончились, но вы пишите, решим 🙂
14.30-15.00 Мастер-класс
Тут выступит наш сертифицированный архитектор Splunk Илья Шаманов. С животрепещущей темой “Механизмы ускорения поисковых запросов в Splunk”. Да, несомненно, Splunk быстрый, но можно заставить его работать еще быстрее!
Мастер-класс рассчитан на продвинутых пользователей Splunk
Будут перечислены три основных механизма: Report Acceleration, Summary Index, Data Model.
Мы предусмотрели сквозную демонстрацию на основе живого примера:
- Берем “тяжелый запрос” и запускаем без ускорения. Визуализируем результаты работы.
- Применяем Report Acceleration: обсуждаем достоинства и недостатки, измеряем ускорение.
- Применяем Summary Index: обсуждаем достоинства и недостатки, измеряем ускорение
- Показываем Data Model: обсуждаем достоинства и недостатки, измеряем ускорение.
- Резюмируем. Сравниваем подходы, обсуждаем достоинства и недостатки, анализируем получаемые ускорения.
Полная программа доступна по ссылке. Ждем вас 30 октября, будет интересно!