COVID FEEDS
Содержание
Что произошло

27 марта известный агрегатор Security Feeds – Anomali опубликовал отчет об использовании в атаках индикаторов, связанных с COVID-19. В первой части отчета содержится краткий анализ видов атак и тактик их проведения с учетом пандемии. Однако, наше внимание привлекла вторая часть отчета – список обнаруженных на момент публикации индикаторов компрометации (IOCs). И мы решили взглянуть на него поподробнее.
Для далеких от Threat Intelligence читателей стоит добавить краткое пояснение. Security Feeds – это списки участвовавших в реальных атаках IP-адресов, доменов, хэшей, названий файлов и т.д (далее – репутационные списки). По сути, это перечень улик, по которому можно с большой вероятностью определить факт атаки при корреляции в SIEM-системе. Обычно репутационные списки делятся по типу индикаторов компрометации и содержат поля, указывающие на степень доверия к этому индикатору (кто нашел, когда, в каких атаках был замечен, ссылка на источник). С помощью этих полей можно ранжировать степень доверия к индикатору и повышать\понижать критичность связанных с ним инцидентов, отсюда и «репутационные» в названии. Далее мы проведем небольшой анализ опубликованных данных, обработаем их для использования в SIEM и рассмотрим основные кейсы применения с учетом технических вопросов.
Обработка данных
Внимание! Далее описывается сугубо техническая информация о процессе обработки данных, которая будет интересна исключительно ETL-инженерам. При желании можно пропустить этот раздел и сразу перейти к разделу Анализ данных, там классно.
При ближайшем рассмотрении опубликованного репутационного списка оказалось, что в текущем виде его будет сложно использовать – плохо разделены категории, в данных встречаются ошибки и т.д. Поэтому с помощью Splunk и напильника захотелось сделать готовый к применению инструмент, который вы сможете добавить в любой SIEM, вне зависимости от производителя и возможностей.
Для начала рассмотрим модель данных исходного списка. Список состоит из 7 полей:
- Date Reported – дата обнаружения индикатора в формате мм/дд/гг;
- Indicator – сам индикатор, формат меняется в зависимости от типа;
- Type – тип индикатора. Варианты:
- Ссылка (URL);
- Домен (Domain);
- Доменное имя (Hostname);
- IP-адрес (IP Address);
- Хэш в формате SHA-1 (SHA-1);
- Хэш в формате SHA-256 (SHA-256);
- Хэш в формате MD5 (MD5);
- Хэш в формате SSDEEP (SSDEEP);
- Имя файла (File Name);
- Тема электронного письма (Subject Line);
- Электронный адрес (Email Address).
- Comments – краткое описание типа атаки и/или сопоставление APT-группировки;
- Source – источник, с помощью которого выявлен индикатор;
- Source URL – ссылка на источник обнаружения индикатора.
Особое внимание стоит уделить полю «Type» – разделение на отдельные типы Url, Domain и Hostname, как и использование нескольких сущностей для хэшей не имеет практического смысла. Обычно при работе с репутационными списками, SIEM инженеры настраивают сравнение всего поля события или его части с полем из списка. В связи с этим имеет смысл выделить несколько уникальных типов, по которым в дальнейшем будут строиться корреляции и добавить новое поле «Subtype» в котором будет хранится тип хэша или тип ссылки, если кому-то они в будущем понадобятся.
После проведенных манипуляций у нас получилось 6 основных типов:
- URL;
- IP Address;
- Hash;
- File;
- Subject Line;
- Email Address.
Посмотрим на поле «Date Reported» – такой формат даты («мм/дд/гг») встречается очень редко, а SIEM-системы обычно используют либо более распространенные форматы, либо Epoch Time. Так как возможности извлечения дат отличаются от решения к решению, а наша задача – универсальность, то проще использовать Epoch формат, который смогут распознать все. Таким образом, поле «Date Reported» с датой «12/3/20» превратилось в поле timestamp с содержимым «1585947600».
Далее, в процессе изучения данных внезапно оказалось что формат содержимого поля «Indicator» отличался от строки к строке и данные пришлось дополнительно очищать от различных артефактов. Например, избавляться от экранирования точек в ip-адресах: 69[.]172[.]75[.]223 -> 69.172.75.223 и подобных проблем.
После очистки данных поля были финально отсортированы и переименованы.В итоге получилась следующая модель данных:
| timestamp | ioc | type | subtype | comments | source | source_url |
| 1584219600 | 64551b04da5c87e5ecaa8e315cdd186fac570fbf47ad3cf5eb3daf4b1138859d | Hash | SHA256 | Malspam using … | MalwareBytes | https://twitter.com/MBThreatIntel/status/1239253487369605120 |
Для сравнения старая модель:
| Date Reported | Indicator | Type | Comments | Source | Source Url |
| 3/15/20 | 64551b04da5c87e5ecaa8e315cdd186fac570fbf47ad3cf5eb3daf4b1138859d | SHA-256 | Malspam using … | MalwareBytes | https://twitter.com/MBThreatIntel/status/1239253487369605120 |
Полей стало на 1 больше, но существенно повысилась универсальность и применимость списка, он может использоваться в любом решении без дополнительной настройки. Дополнительно были сформированы одномерные списки по каждому типу индикаторов для максимально быстрой интеграции с любым SIEM-решением:
- covid_feeds_url
- covid_feeds_hash
- covid_feeds_ip
- covid_feeds_file
- covid_feeds_email_subject
- covid_feeds_email_address
Данные репутационные списки можно скачать отсюда
Подводя итог обработки, получилось сделать следующее:
- Объединены похожие типы индикаторов. [URL, Domain, Hostname -> URL]
- Объединены в один тип «Hash» все хэши. [SHA-1,SHA-256,MD5, SSDEEP -> Hash]
- Добавлено поле «subtype», в котором содержатся дополнительные пояснения к типу.
- Очищены и преобразованы индикаторы в поле «Indicator».
- Изменен формат временной метки. [мм/дд/гг -> Epoch]
- Переименованы поля для более удобной интеграции в SIEM.
- Сформирован один итоговый список со всеми типами и отдельные одномерные списки по кажому типу индикаторов.
Анализ данных
Для анализа будем использовать уже обработанный список «covid_feeds_all» . Он содержит более 3000 записей в формате csv и разделен на 7 полей:
- timestamp – дата обнаружения индикатора;
- ioc – сам индикатор, меняющийся в зависимости от типа;
- type – тип индикатора;
- subtype – подкатегория индикатора, например алгоритм для типа «Hash»;
- сomments – краткое описание типа атаки и/или сопоставление APT-группировки;
- source – источник, с помощью которого выявлен индикатор;
- source_url – ссылка на источник индикатора.
Начнем с анализа дат появления индикаторов. Если построить график по полю «timestamp» с периодом в 1 неделю, то получится следующее:

Рисунок 1. Распределение IOCs по времени появления
Как видно из графика, первые появления датированы началом декабря, задолго до мирового распространения вируса, а пик пришелся на момент введения карантина в большинстве стран, то есть примерно на середину марта. Скорее всего, такое распространение связано не с появлением большого количества новых ресурсов, а с началом массовых сканирований, что косвенно подтвержает количество индикаторов по источникам. Но не будем играть в серьезных аналитиков, которых сейчас хватает, и подумаем о технической стороне вопроса и о том, как можно использовать данную информацию в SIEM. Самая большая проблема использования репутационных списков – они часто врут. Конечно, это не совсем так, и многое зависит от вендора списка, но факт остается фактом – при подключении большинства списков количество ложно-положительных срабатываний корреляционных правил возрастает в разы и аналитики начинают захлебываться в потоке инцидентов. Есть несколько методов борьбы с проблемой и они будут рассмотрены позже, но в рамках текущего анализа дат интересен только один метод – введение коэффициента доверия к индикатору. Серьезные коммерческие производители реализуют данный функционал прямо в составе репутационных списков отдельным полем, их оценка комплексная и включает в себя несколько факторов, таких как:
- доверие к источнику индикатора;
- частота реального использования в атаках;
- частота ложно-положителных срабатываний;
- актуальность (время появления);
- и т.д.
Часть данного функционала довольно просто реализовать в рамках SIEM-системы – достаточно ввести время жизни индикатора (TTL) по истечению которого он перестает участвовать в корреляции. Данный функционал поддерживается большинством решений и его настройка не займет много времени.
Вернемся к анализу и попробуем посмотреть на распределение по типам индикаторов. Построим статистику по полю «type»:
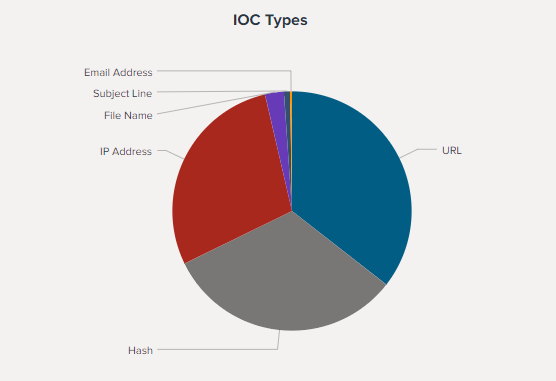
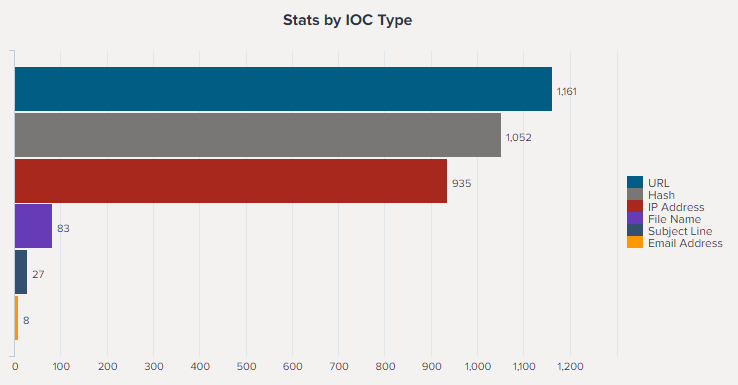
Абсолютное большинство индикаторов относится к 3 типам:
- URL (36%);
- Hash (32%);
- IP-address (29%).
Такое соотношение легко объясняется спецификой атак – большинство из них связано с фишингом. Более подробно тактики рассмотрены в базовом отчете Anomali, нам же данная информация позволяет сформировать перечень основных источников данных, при наличии логов которых в SIEM мы сможем эффективно использовать репутационный список.
- источники для типа «URL»: прокси-серверы, межсетевые экраны класса NGFW (Next Generation Firewall), UTM (Unified Threat Management), IDS/IPS, включая HIPS, DLP-системы с модулями контроля Интернет-активности сотрудников;
- источники для типа «Hash»: решения класса Sandbox, антивирусное ПО, программное обеспечение, предназначенное для расширенного аудита клиентских операционных систем (например – Sysmon), агенты SIEM систем или СЗИ от НСД;
- источники для типа «IP Address»: межсетевые экраны, IDS/IPS, прокси-серверы, активное сетевое оборудование.
Остальные типы находятся в рамках погрешности (менее 5% в сумме), поэтому источники мы им подберем, но отметим как дополнительные (*):
- источники для типа «File Name»: Клиентские средства защиты от несанкционированного доступа, Sysmon, Антивирусное ПО;
- источники для типа «Subject Line»: Почтовый сервер, Средства защиты корпоративной почты от спама.
- источники для типа «Email Address»: Почтовый сервер, Средства защиты корпоративной почты от спама.
Сформируем итоговую таблицу источников с ссылками на тип списка, который необходимо использовать:
| № | Тип списка | Источники | Используемый список |
| 1 | URL | Прокси-серверы Межсетевые экраны класса NGFW (Next Generation Firewall), UTM (Unified Threat Management) IDS/IPS (Включая HIPS) DLP-системы с модулями контроля Интернет-активности сотрудников | covid_feeds_url |
| 2 | Hash | Решения класса Sandbox Антивирусное ПО Sysmon СЗИ от НСД | covid_feeds_hash |
| 3 | IP Address | Межсетевые экраны IDS/IPS Прокси-серверы Активное сетевое оборудование | covid_feeds_ip |
| 4 | File Name* | Клиентские средства защиты от несанкционированного доступа Sysmon Антивирусное ПО | covid_feeds_file |
| 5 | Subject Line* | Почтовый сервер Средства защиты корпоративной почты от спама | covid_feeds_email_subject |
| 6 | Email Address* | Почтовый сервер Средства защиты корпоративной почты от спама | covid_feeds_email_address |
Применение
Определившись с источниками, необходимыми для работы, перейдем к методам использования «нашего» репутационного списка. Попробуем описать типовой механизм интеграции:
- В зависимости от собираемых в SIEM логов выбираем источники и определяемся с видами списков, которые планируем использовать.
- В зависимости от SIEM-системы добавляем один или несколько списков в качестве внутреннего объекта системы (Splunk – Lookup, ArcSight – Active List, Qradar – Reference Set, MP SIEM – Табличный список).
- Используем для корреляции, сравнивая поле события со значением из репутационного списка или же определяя вхождение записи из списка в поле.
Например, при сравнении поля «URL» от источника Proxy со значением «coronavirus-map.com» из списка, необходимо детектировать ссылки вида «subdomain.coronavirus-map.com».
Стоит подробнее остановится на возможном использовании списков. Самый простой способ описан выше – создавать инцидент на каждое срабатывание, но такой метод генерирует большое количество ложно-положительных срабатываний. Поэтому стоит рассмотреть несколько вариантов оптимизации при работе с репутационными списками:
- Ограничить применимость корреляционного правила для определенных пользователей\активов. Стандартный способ уменьшения количества ложных срабатываний для SIEM-системы. Максимально простой вариант для реализации, но часть срабатываний теряется.
Пример: ограничение правила на срабатывание только для критичных учетных записей. - Использовать в составе существующих правил, но с повышением критичности инцидентов. Хороший метод для работы с TI-источниками, актуальный для большинства компаний. Позволяет существенно снизить нагрузку на аналитиков за счет приоретизации инцидентов.
Пример: добавление условия в правило для критичных активов, повышающее его Severity до максимального. - Использовать в качестве дополнительного параметра при скоринге риска. Похоже на предыдущий пункт, но актуально только для команий, использующих скоринг системы на базе SIEM, либо Splunk или Smart Monitor. Если в рамках SIEM построена риск-модель, отслеживающая все срабатывания для УЗ\активов, то мы создаем новое правило, в результате которого повышается общий скоринг объекта, но не создается инцидент.
- Ввести TTL для записей репутационного списка. Уменьшая время жизни записей в списке, мы уменьшаем количество срабатываний и реагируем только на актульные угрозы.
Также хотелось бы отметить, что использование репутационных списков не ограничивается исключительно SIEM-системой. Многие современные СЗИ поддерживают подобные инструменты.
Примеры:
- можно добавить email из репутационного списка в базы спам-фильтров почтовых серверов и средств защиты от спама;
- легко контролировать e-mail сообщения с темами писем из категории «covid_feeds_email_subject». При использовании правил транспорта сообщений, можно направлять копии подозрительных писем на отдельный e-mail для дальнейшей проверки аналитиками ИБ. Также может быть использован подход с использованием утверждений модератором потенциально вредоносных сообщений;
- IP-адреса и URL из репутационного списка легко добавляются в запрещающие правила прокси-серверов и межсетевых экранов и вообще не требуют внимания аналитиков.
В заключение, хотелось бы отметить, что правильное применение репутационных списков и\или Threat Intelligence платформ существенно увеличивает потенциал SIEM-систем. Использование индикаторов, которые применяются в реальных атаках помогает выявлять даже атаки, не описанные в рамках корреляционных правил, существенно уменьшать количество ложно-положительных срабатываний и нагрузку на аналитиков.